
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
车祸是我们世界的一大问题。国际上每年有近130万人死于车祸,此外还有多达5000万人受伤。机器学习能帮助拯救生命吗?我相信答案是肯定的,在这个教程里,我们将给出一种可能的方法。
许多政府机构都回收集交通事故记录,并公开这些数据。此外,还有许多道路基础设施数据集。我们将利用公开提供的道路基础设施数据和天气数据源,尝试使用有监督机器学习来预测Utah州内每小时每个路段的事故风险。
1、预测交通事故的方法
我们将交通事故风险预测视为一个分类问题,事故和无事故。也可以视为回归问题(事故数量),但在我们选择的时间尺度(一小时),预计每个路段不会超过一次事故,因此视为分类问题会稍稍简化。当然还有其他方法,但这就是我们在这里采取的方法。通常流量采用 Poisson 或负二元模型。选择一个小的路段和时间间隔,使我们能够将每个观察结果视为伯努利随机变量(因此使用交叉熵损失函数作为目标)
我们可以用七年内约五十万条车祸记录作为正样本。你可能会问,负样本在哪里?问得好!每个路段/小时组合都可能是负样本。超过 7 年和 400,000 个离散路段,这相当于大约 245 亿个潜在的副样本。
机器学习从业者会注意到这里的一个问题,即类样本不平衡。严重的类不平衡。从本质上讲,如果我们使用所有这些数据来训练一个模型,我们的模型将严重偏向于没有事故。如果我们想要估计交通事故风险,这是一个问题。
为了解决这个问题,我们不再使用所有 245亿 负样本,而是采取采样方法,稍后将在本文中详细介绍。
2、探索交通事故数据
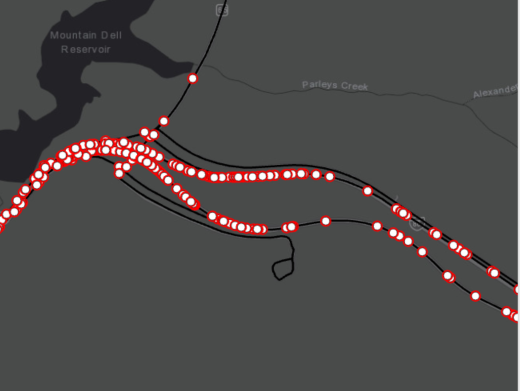
近 50 万起事故是什么样子的?
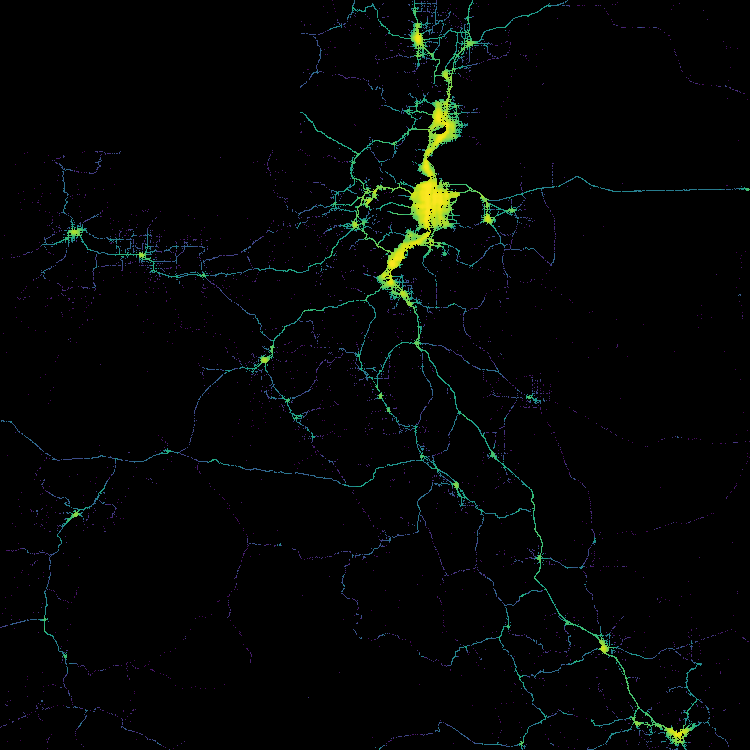
任何需要通勤的人都绝对了解时间对车祸的影响。我们可以在下图可视化 7 年事故的模样:
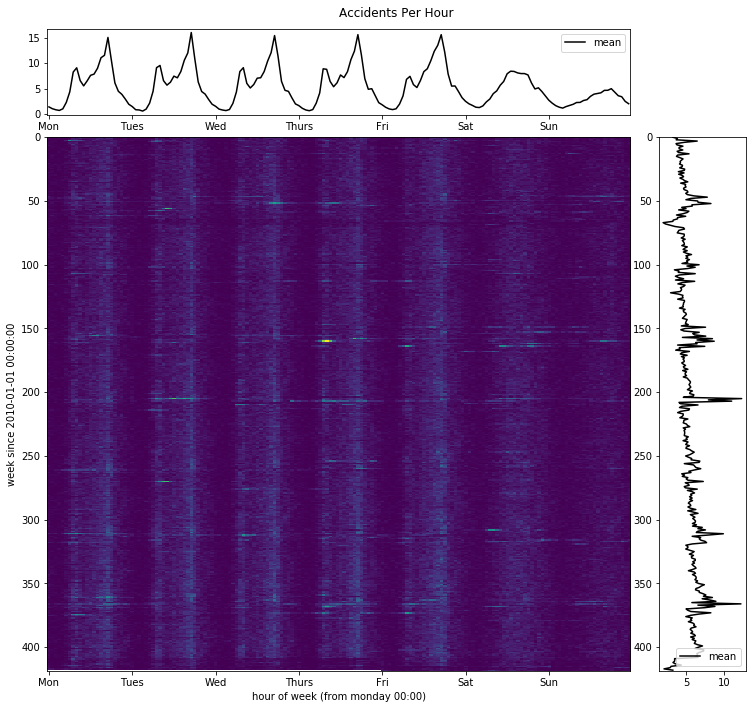
这符合我们的直觉:事故大多发生在工作日下午的高峰时段。通过观察垂直横截面的另一个观察是,事故往往在12月~1月的时间范围内达到高峰。犹他州在这段时间里经常有大雪和冰,所以这当然不是意外。这突出了天气数据作为该模型输入的重要性。犹他州在高峰时段平均每天发生15起事故。
3、设计交通事故预测的输入
现在我们知道了要预测什么了,输入是什么?什么会导致车祸。当然,答案是许多因素,其中一些因素我们包括在本次分析中。
- 天气(温度、风速、能见度、雨/雪/结冰、积雪深度、降雨量等)
- 时间特征:一天中的小时、一周中的天、一年中的月份、太阳的方位/海拔
- 静态特征,如限速、道路曲率、平均交通量、靠近交叉路口、道路南北/东/西路线、道路宽度、路面类型等
- 人为因素,如人口密度和广告牌之类容易分散注意力的设施
- 道路网络的图形衍生特征,如中心和流量
- 无数的其他因素
这就是此分析的地理空间部分变得重要的地方。这本质上是一个空间问题,我们的机器学习模型需要考虑许多不同的地理空间数据源及其彼此之间的关系。这将包括许多地理操作,这些操作的计算成本可能很高。为此,我使用 ArcGIS 平台。
输入实际上有两个不同的部分:静态功能和动态功能。
静态特征是输入数据的一部分,在大多数情况下,这些不会随时间而改变。这包括从道路几何学中得出的特征。而另外一些特征,如曲率或其他属性,如限速或人口密度,当然不是静态的,但是它们只是慢慢改变,所以我们可以把它们视为常数。
动态特征和我们出预测的时间有关,包括天气数据、太阳几何和时间变量(小时、月、日等)。
我们需要计算每个路段的所有这些特性,其中我们大约有400,000个。我们使用Arcgis Pro 包含的 Arcpy Python 库编写了此过程的脚本。让我们快速看看这方面的一个例子:
billboards_url = 'https://maps.udot.utah.gov/arcgis/rest/services/FI_Mandli2012/MapServer/2'
# Calc proximity to billboard
_ = arcpy.analysis.Near('centerlines_merged',
billboards_url)
_ = arcpy.management.CalculateField('centerlines_merged','proximity_to_billboard','!NEAR_DIST!')
_ = arcpy.management.DeleteField('centerlines_merged',['NEAR_DIST','NEAR_FID'])上述代码片段使用"Near"工具查找我们中心线数据中每条道路的最近广告牌的位置。通过计许多基于接近的特征,形成我们的静态特征数据集。
我们还必须从道路几何本身中获取特征。例如,为了估计道路曲率,我们使用"正弦"作为衡量标准。正弦是路径长度与终点之间最短距离之间的比率。再次,使用 Arcpy,我们计算了这一点:
# Calc Sinuosity
code_block = \
'''
import math
def getSinuosity(shp):
x0 = shp.firstPoint.x
y0 = shp.firstPoint.y
x1 = shp.lastPoint.x
y1 = shp.lastPoint.y
euclid = math.sqrt((x0-x1)**2 + (y0-y1)**2)
length = shp.length
if euclid > 0:
return length/euclid
return 1.0
'''
_ = arcpy.management.CalculateField('centerlines_merged','sinuosity','getSinuosity(!Shape!)',code_block=code_block)现在让我们来谈谈天气。有许多不同的天气数据源,但我们选择使用NOAA的可靠的每小时天气数据。我们有几个气象站,但我们需要了解每个路段的天气。一种方法是将地面站的天气插值到各个路段。为此,我们可以在地理统计学社区或机器学习社区中高斯过程回归的称为"Kriging"的技术。
ArcGIS 在地理统计学工具箱中内置了"经验贝叶斯Krigin"工具,该工具包含该技术的强力实现,基于数据使用先验分布,并删除了大量参数调整。如果这不是你的一个选项,还有其他技术,如反向距离加权或简单的空间连接(我这样做最初是为了简单)。如果你有其他数据可以更精确地估计地理如何影响天气特征(如海拔或更复杂的气候模型),你可以将这些数据加载到地理加权回归模型中,以获得更高的准确性。

总之,为构建事故预测的有用特征集我们进行了大量空间操作。然后,这些特征将用于为有监督机器学习模型创建一套训练集。
4、准备交通事故训练集
随着地理空间处理的完成,我们可以把注意力转向实际构建训练集。为此,我们使用 ArcGIS Python API、Pandas和其他一些 Python 库。其中大部分是标准数据处理,但其中任何一项工作的关键部分是创建负样本:即,什么是事故发生时的反例。
一种方法是随机抽样一些没有发生交通事故的道路/时间,但这有一些不足。很多时候,道路事故并不经常发生,但要解决的更重要的问题是区分事故与不发生事故的公路。是什么导致了事故?
我们选择使用抽样方法,建立一组与我们的正样本非常相似的负样本,以便机器学习模型能够学会发现何时发生事故与何时发生事故之间的细微差别。当然,也有随机性的元素,所以我们也会采样非常不同的情况。方法如下:
- 从正面示例中随机选择交通事故记录
- 随机更改:路段、一天中的小时或一年中的一天。
- 如果事故记录中没有新样本,则添加到副样本列表中
- 重复,直到我们有大量的负样本(是正样本数的数倍)
这为我们提供了一套具有挑战性的训练集,因为很难区分正面和负面的样本,我们关心实际的结果。这是一种常用的方法,用于此类情况。
ohe_fields=['one_way','surface_type','street_type','hour','weekday','month']
# One-Hot encode a couple of variables
df_ohe = pd.get_dummies(df,columns=ohe_fields)
# Get the one-hot variable names
ohe_feature_names = pd.get_dummies(df[ohe_fields],columns=ohe_fields).columns.tolist()
df_ohe.head()如上面代码所示,诸如小时、工作日和月份等绝对变量采用one-hot编码。所有连续变量都使用scikit-learn的StandardScaler转换为 z -score。我们还通过对数转换来处理正弦,因为大多数值接近 1,我们希望捕捉到更多的小的差异。
5、构建交通事故预测模型
我采用的机器学习方法是梯度提升,采用了XGBoost库。这种方法建立在一个非常直观的机器学习概念之上,称为决策树。决策树的工作,通过发现不同特征的分裂,分开样本。不幸的是,决策树倾向于过度拟和训练集,这意味着它们不会泛化到新数据,而新数据是预测模型的关键部分。梯度提升通过结合许多不同的决策树的结果在一起,极其快速和强大的。梯度提升通常比许多不同问题的其他方法都好,并且应该放到任何数据科学家的工具箱中。XGBoost 是梯度提升的特别好实现。我们还训练了其他模型,包括深度神经网络,但发现梯度提升不仅提供了最佳的整体性能 (ROC AUC),它还让我们更深入地了解决策的产生原因。应当指出,我们构建的深度神经网络以同等精度实现了更高的召回。
我不会详细介绍超参数优化和训练,但以下是最终的模型选择:
params = {
'max_depth':6,
'min_child_weight': 5.0,
'reg_lambda': 1.0,
'reg_alpha':0.0,
'scale_pos_weight':1.0,
'eval_metric':'auc',
'objective':'binary:logistic',
'subsample':0.8,
'eta':0.3
}我们训练到收敛10轮停止,得到的ROC AUC约0.828。最终的模型包含80棵树。
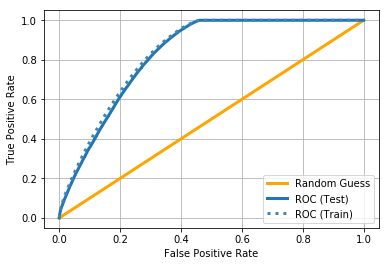
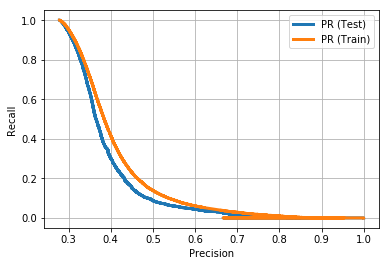
阈值为 0.19,获得以下性能指标:
Test Accuracy: 0.685907494583
Test F1: 0.461524665975
Test Precision: 0.311445366528
Test Recall: 0.890767937497
Test AUC: 0.828257459986
Test AP: 0.388845428164
Train Accuracy: 0.68895115694
Train F1: 0.466528546103
Train Precision: 0.314947399182
Train Recall: 0.899402111551
Train AUC: 0.836489144112
Test AP: 0.410456610829就像我之前说过的,我们故意使训练集难以分开,因为我们希望结果能够反映模型的真实性能。召回值为 0.89 意味着我们能够预测近 90% 的车祸,而 0.31 的精确值意味着我们大约 30% 的时间对这些预测是正确的。这不是完美的,但它是一个很好的开始,肯定告诉我们一些关于我们预测事故的能力。我们可以做很多事情来提高这个模型的性能,也许我会在未来的帖子中重新审视这一点。
6、一些结果
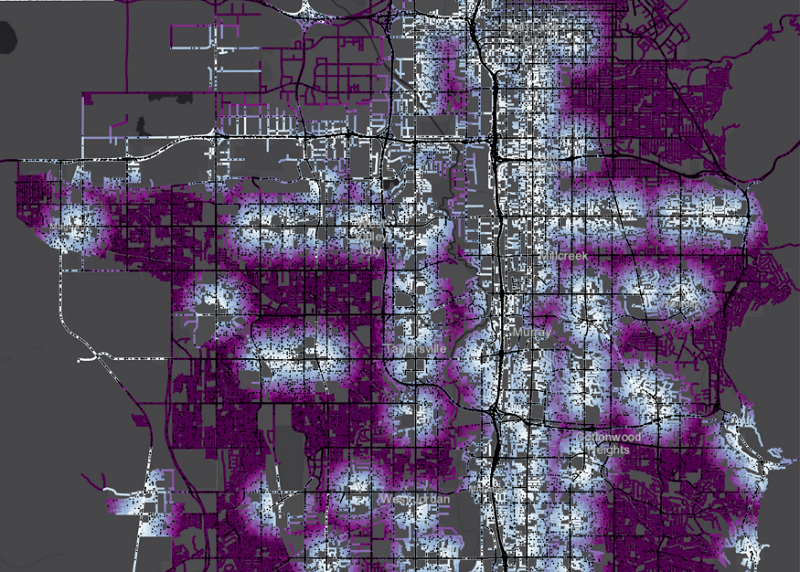
太好了, 现在我们有一个模型, 实现了不错的性能, 我们可以收集关于这个模型如何作出预测?使用哪些特征?哪些值很重要?
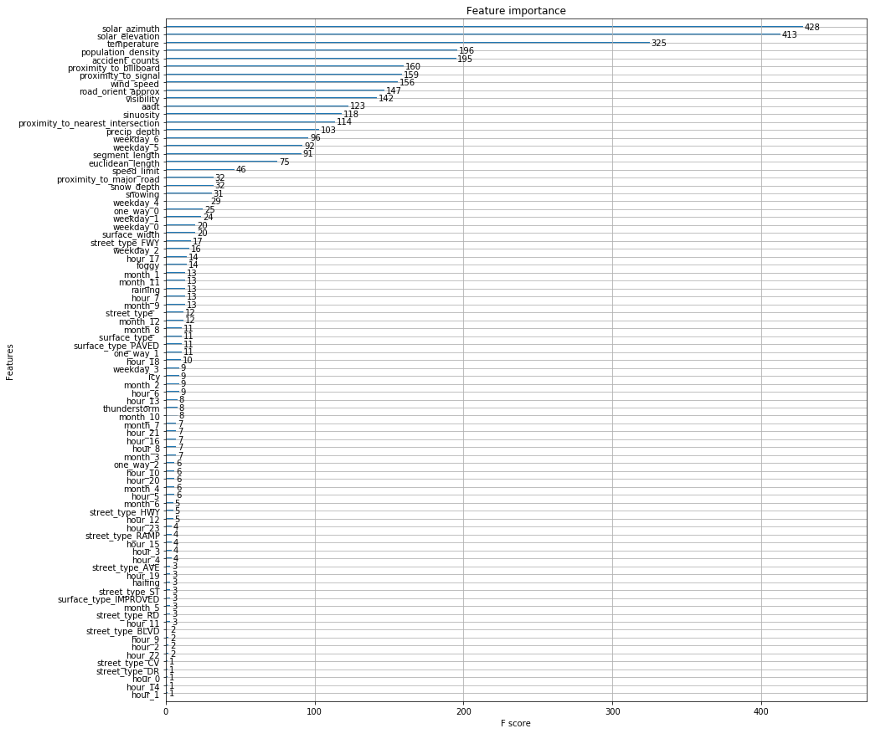
从上面的图中可以看出太阳的位置和温度是最重要的。有几个原因可以说明为什么这些都是重要的特征。温度是难以测量事物的代理变量。例如,温度与季节和一天中的时间有关。它还告诉我们道路结冰的可能性有多大。
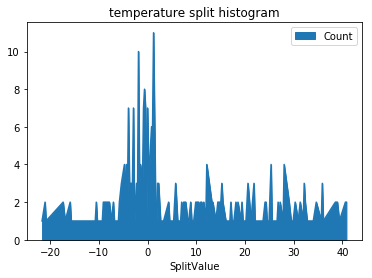
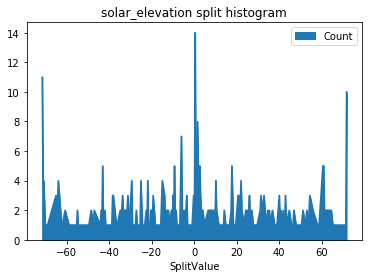
显然,太阳的位置告诉我们一天的时间和季节,但它也允许我们建模一个有趣的因素:太阳是否在照射司机的眼睛?让我们来看看太阳高程和道路方向的分形直方图。
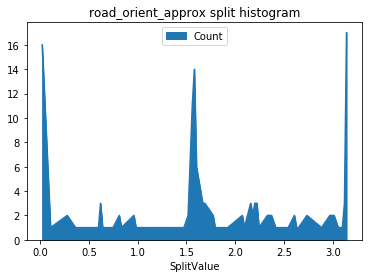
在列表中,我们注意到population_density、accident_counts、proximity_to_billboard、proximity_to_signal是重要特征。从我们的分析中,这些当然有意义。拟可能会注意到小时、工作日和月份通过one-hot编码被分解成多个特征。如果我们从每小时汇总重要性,它们实际上对模型做出了巨大贡献。不太常见的天气特征,如结冰(不经常在我们的天气数据中报告)等出现在模型中,但对预测结果不太有用。
我们模型的时效性能如何?它能随着时间推移做出预测吗?
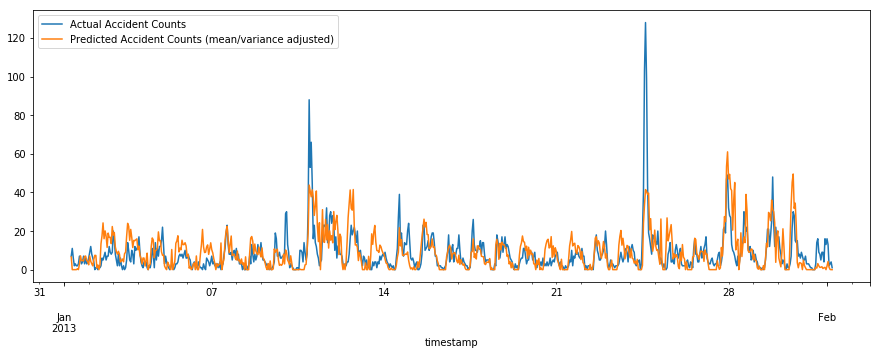
请记住,这不是一个时间系列模型,我们只是估计所有路段的预期计数,并聚合它们。我们对由此产生的时间系列进行平均/差异调整,因为我们有一套偏向于事故的训练集。
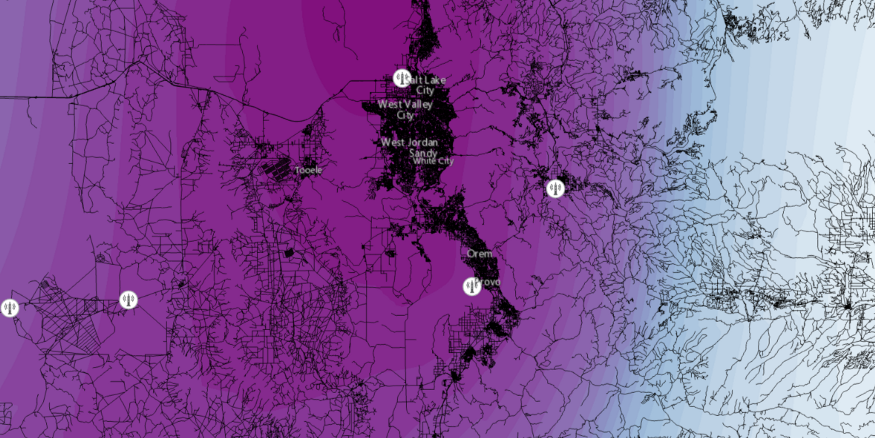
最后,让我们从空间上查看生成的模型。
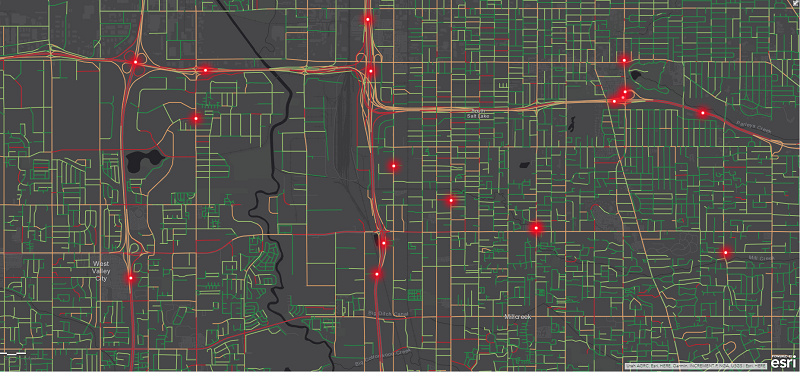
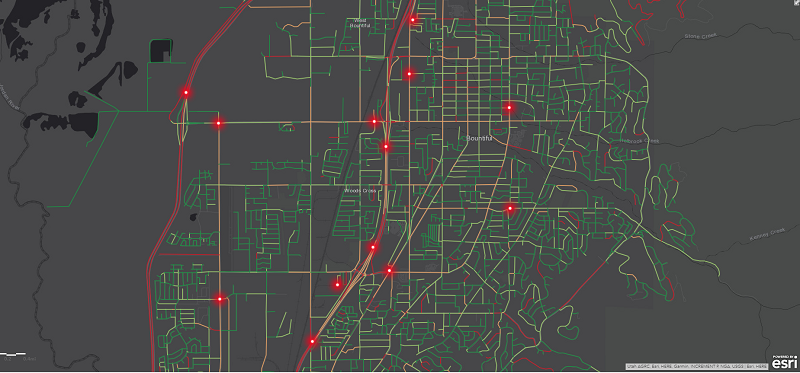
你会从上面的图形中注意到,有很多地方,我们预测为高风险,但没有事故。我们正试图使用此模型量化风险,但事故仍然是随机发生的。我们相信,随着更多的特征,特别是实时交通信息,施工,重要事件,更高的分辨率天气等,我们可以大大改善这一模式,但它是良好的开始。
原文链接:Using Machine Learning to Predict Car Accident Risk
BimAnt翻译整理,转载请标明出处





