
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
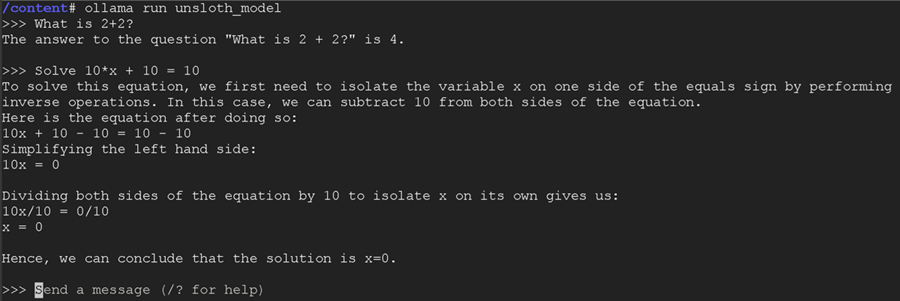
本教程将通过使用 Unsloth 免费微调 Llama-3 来创建自定义聊天机器人。它可以通过 PC 上的 Ollama 在本地运行,也可以通过 Google Colab 在免费的 GPU 实例中运行。你将能够以交互方式与聊天机器人交互,如下所示:
Unsloth 使微调变得更加容易,并且可以通过集成的自动模型文件创建将微调后的模型自动导出到 Ollama!
1、什么是 Unsloth?
Unsloth 使 Llama-3、Mistral、Phi-3 和 Gemma 等 LLM 的微调速度提高 2 倍,内存使用量减少 70%,并且准确度不会降低!我们将在本教程中使用提供免费 GPU 的 Google Colab。你可以访问以下免费笔记本:
- Ollama Llama-3 Alpaca(我们将使用的笔记本)
- CSV/Excel Ollama 指南
你还需要登录 Google 帐户!
2、什么是 Ollama?
Ollama 可让你快速简单地从自己的计算机运行语言模型!它会悄悄启动一个程序,该程序可以在后台运行 Llama-3 等语言模型。如果你突然想向语言模型提问,只需向 Ollama 提交请求,它就会快速将结果返回给你!
我们将使用 Ollama 作为我们的推理引擎!
3、安装 Unsloth
如果你从未使用过 Colab 笔记本,请快速入门笔记本本身:
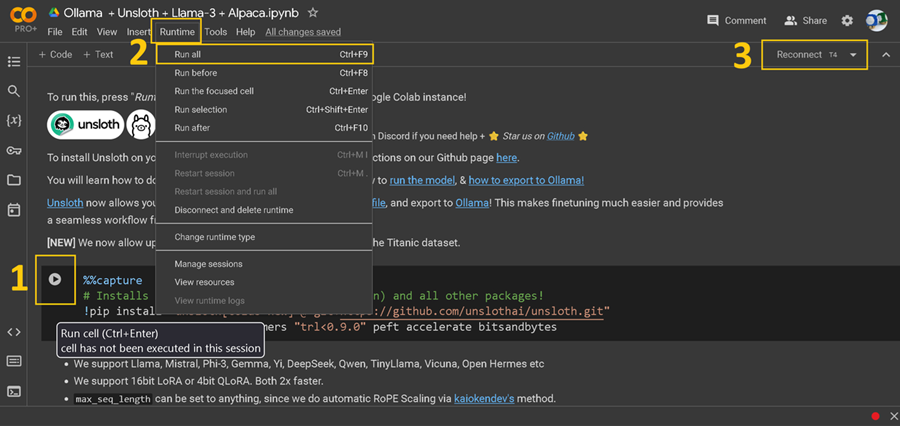
- 每个“单元”上的播放按钮。单击此按钮可运行该单元的代码。您不能跳过任何单元,并且必须按时间顺序运行每个单元。如果遇到任何错误,只需重新运行之前未运行的单元即可。如果您不想单击播放按钮,另一个选项是单击 CTRL + ENTER。
- 顶部工具栏中的运行时按钮。您还可以使用此按钮并点击“全部运行”一次运行整个笔记本。这将跳过所有自定义步骤,并且可以成为一次不错的初次尝试。
- 连接/重新连接 T4 按钮。您可以单击此处获取更高级的系统统计信息。
第一个安装单元如下所示:请记住单击括号 [ ] 中的播放按钮。我们获取我们的开源 Github 包,并安装一些其他包。

4、选择要微调的模型
现在让我们选择一个要微调的模型!我们默认使用 Meta / Facebook 的 Llama-3,它经过了高达 15 万亿个“token”的训练。假设一个 token 相当于 1 个英文单词。这大约相当于 350,000 本厚厚的百科全书!其他流行的模型包括 Mistral、Phi-3(使用 GPT-4 输出进行训练)和谷歌的 Gemma(13 万亿个 token!)。
Unsloth 支持这些模型以及更多!事实上,只需从 Hugging Face 模型中心输入一个模型,看看它是否有效!如果它不起作用,我们会出错。
还有 3 个其他设置可以切换:
max_seq_length = 2048。这决定了模型的上下文长度。例如,Gemini 的上下文长度超过 100 万,而 Llama-3 的上下文长度为 8192。我们允许您选择任意数字 - 但出于测试目的,我们建议将其设置为 2048。Unsloth 还支持非常长的上下文微调,并且我们表明我们可以提供比最佳长度长 4 倍的上下文长度。dtype = None。将其保留为 None,但对于较新的 GPU,您可以选择 torch.float16 或 torch.bfloat16。load_in_4bit = True。我们以 4 位量化进行微调。这将内存使用量减少了 4 倍,使我们能够在免费的 16GB 内存 GPU 中实际进行微调。4 位量化本质上将权重转换为一组有限的数字以减少内存使用量。这样做的缺点是准确度会下降 1-2%。如果您想要这种微小的额外准确度,请在较大的 GPU(如 H100)上将其设置为 False。

如果你运行该单元,你将获得一些 Unsloth 版本的打印输出,包括你正在使用的模型、你的 GPU 有多少内存以及一些其他统计数据。暂时忽略这些。
5、微调参数
现在要自定义微调,你可以编辑上面的数字,但你可以忽略它,因为我们已经选择了相当合理的数字。
目标是更改这些数字以提高准确性,同时也抵消过度拟合。过度拟合是指你让语言模型记住数据集,而无法回答新颖的新问题。我们希望最终模型能够回答看不见的问题,而不是进行记忆。
r = 16,# 选择任何数字 > 0 !建议 8、16、32、64、128微调过程的等级。数字越大,占用的内存越多,速度越慢,但可以提高更困难任务的准确性。我们通常建议数字为 8(用于快速微调),最高可达 128。数字过大可能会导致过度拟合,损害模型的质量。
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj","gate_proj", "up_proj", "down_proj",],我们选择所有模块进行微调。您可以删除一些模块以减少内存使用并加快训练速度,但我们强烈建议不要这样做。只需在所有模块上进行训练!
lora_alpha = 16,微调的缩放因子。较大的数字将使微调更多地了解您的数据集,但可能会促进过度拟合。我们建议将其等于等级 r,或将其加倍。
lora_dropout = 0, # 支持任何,但 = 0 是优化的将其保留为 0 以加快训练速度!可以减少过度拟合,但不会那么多。
bias = "none", # 支持任何,但 = "none" 是优化的将其保留为 0 以加快训练速度并减少过度拟合!
use_gradient_checkpointing = "unsloth", # 对于非常长的上下文,使用 True 或 "unsloth"选项包括 True、False 和 "unsloth"。我们建议使用 "unsloth",因为我们将内存使用量减少了 30%,并支持非常长的上下文微调。你可以在此处了解更多详细信息。
random_state = 3407,确定确定性运行的数字。训练和微调需要随机数,因此设置此数字可以使实验可重复。
use_rslora = False, # 我们支持等级稳定的 LoRA高级功能可自动设置 lora_alpha = 16。您可以根据需要使用它!
loftq_config = None, # 和 LoftQ高级功能可将 LoRA 矩阵初始化为权重的前 r 个奇异向量。可以在一定程度上提高准确性,但一开始会使内存使用量激增。
6、Alpaca 数据集
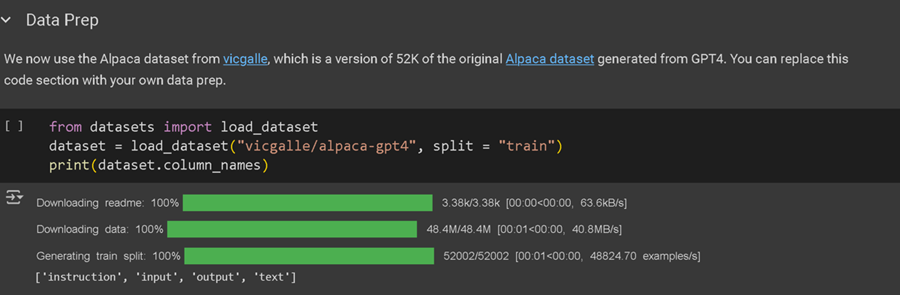
我们现在将使用通过调用 GPT-4 本身创建的 Alpaca 数据集。它是一个包含 52,000 条指令和输出的列表,在 Llama-1 发布时非常受欢迎,因为它使基础 LLM 的微调与 ChatGPT 本身具有竞争力。
你可以在此处访问 Alpaca 数据集的 GPT4 版本。数据集的较旧的第一个版本在这里。下面显示了数据集的一些示例:

你可以看到每行有 3 列 - 一个指令、一个输入和一个输出。我们基本上将每行组合成一个大提示,如下所示。然后我们使用它来微调语言模型,这使得它与 ChatGPT 非常相似。我们将此过程称为监督指令微调。
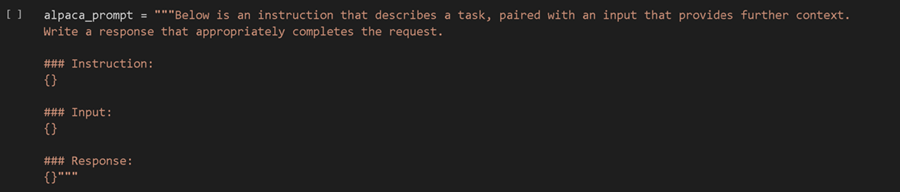
7、用于微调的多列
但对于 ChatGPT 风格的助手来说,一个大问题是,我们只允许 1 条指令/1 个提示,而不允许多列/输入。例如,在 ChatGPT 中,您可以看到我们必须提交 1 个提示,而不是多个提示。
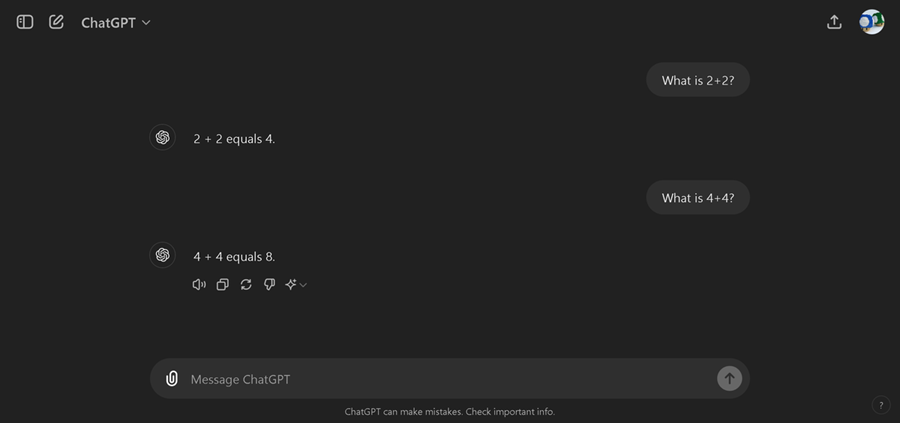
这实际上意味着我们必须将多列“合并”为 1 个大提示,才能使微调真正发挥作用!
例如,非常著名的泰坦尼克号数据集有很多列。你的工作是根据乘客的年龄、乘客等级、票价等预测乘客是幸存还是死亡。我们不能简单地将其传递给 ChatGPT,而是必须将这些信息“合并”为 1 个大提示。

例如,如果我们使用包含该乘客所有信息的“合并”单个提示询问 ChatGPT,那么我们可以要求它猜测或预测乘客是死亡还是幸存。
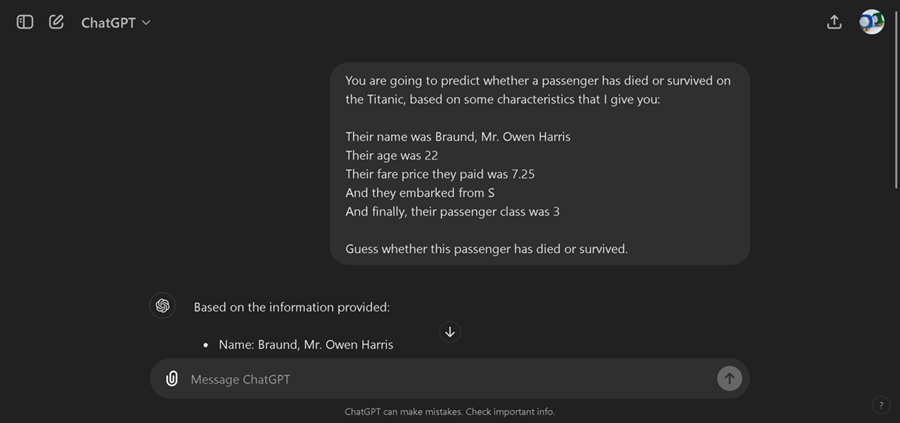
其他微调库要求你手动准备数据集以进行微调,方法是将所有列合并为 1 个提示。在 Unsloth 中,我们只需提供名为 to_sharegpt 的函数,即可一次性完成此操作!
要访问 Titanic 微调笔记本或上传 CSV 或 Excel 文件,请访问这里。
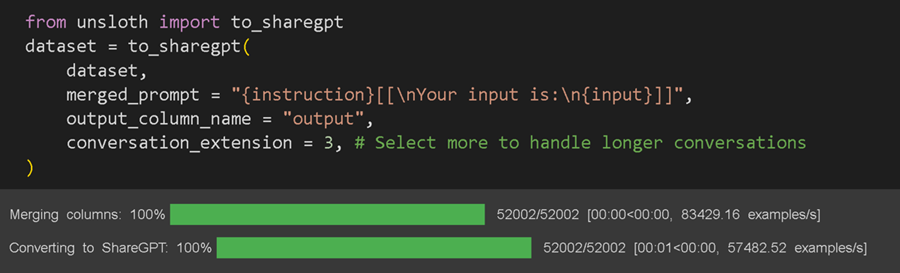
现在这有点复杂,因为我们允许大量自定义,但有几点:
- 你必须将所有列括在花括号
{}中。这些是实际 CSV/Excel 文件中的列名。 - 可选文本组件必须括在
[[]]中。例如,如果列“输入”为空,则合并函数将不显示文本并跳过此操作。这对于缺少值的数据集很有用。 - 在
output_column_name中选择输出或目标/预测列。对于 Alpaca 数据集,这将是输出。
例如,在泰坦尼克号数据集中,我们可以创建一个如下所示的大型合并提示格式,其中每列/文本都是可选的。
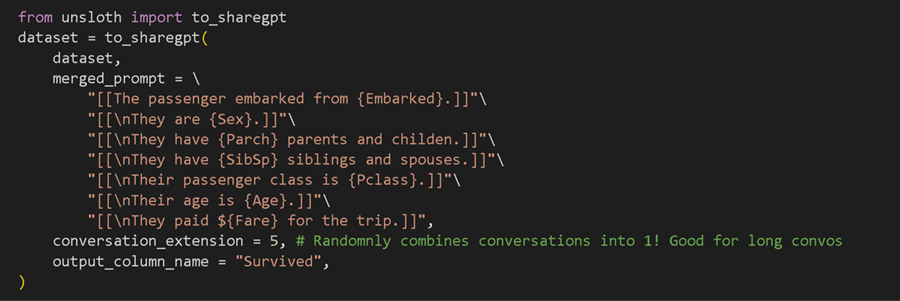
例如,假设数据集看起来像这样,但有很多缺失数据:
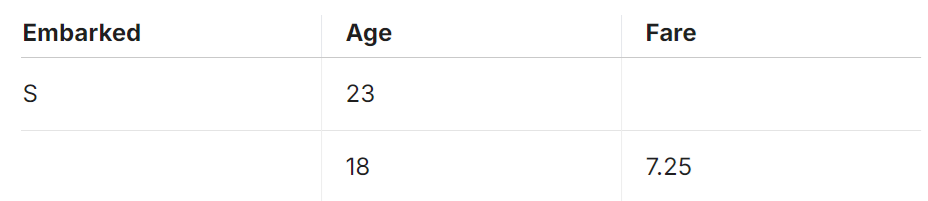
然后,我们不希望结果是:
- 乘客从 S 登船。他们的年龄是 23 岁。他们的票价是空的。
- 乘客从EMPTY登船。他们的年龄是 18 岁。他们的票价是 7.25 美元。
相反,通过使用 [[]] 可选地将列括起来,我们可以完全排除这些信息。
- [[乘客从 S 出发。]] [[他们的年龄是 23 岁。]] [[他们的票价是空的。]]
- [[乘客从 EMPTY 出发。]] [[他们的年龄是 18 岁。]] [[他们的票价是 7.25 美元。]]
变为:
- 乘客从 S 出发。他们的年龄是 23 岁。
- 他们的年龄是 18 岁。他们的票价是 7.25 美元。
8、多轮对话
如果你没有注意到,一个小问题是 Alpaca 数据集是单轮的,而记住使用 ChatGPT 是交互式的,你可以多轮对话。例如,左边是我们想要的,但右边的 Alpaca 数据集只提供单轮对话。我们希望经过微调的语言模型能够以某种方式学习如何像 ChatGPT 一样进行多轮对话。
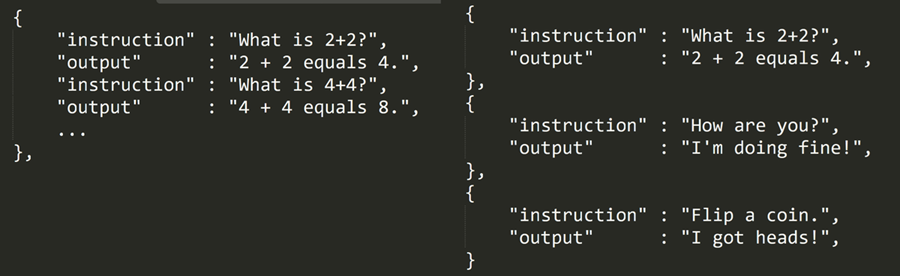
因此,我们引入了 dialogue_extension 参数,它本质上会选择单轮数据集中的一些随机行,并将它们合并为 1 个对话!例如,如果您将其设置为 3,我们会随机选择 3 行并将它们合并为 1 行!将它们设置得太长会使训练速度变慢,但可以使您的聊天机器人和最终微调更好!

然后将 output_column_name 设置为预测/输出列。对于 Alpaca 数据集,它将是输出列。
然后我们使用 standardize_sharegpt 函数将数据集设置为正确的格式以进行微调!始终调用此函数!
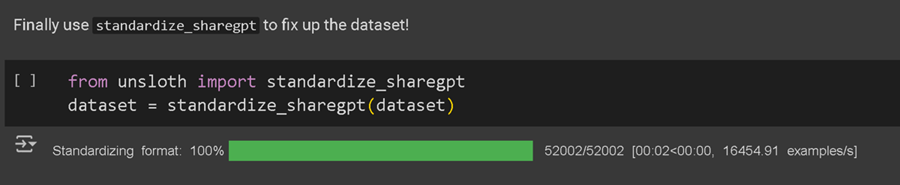
9、可自定义的聊天模板
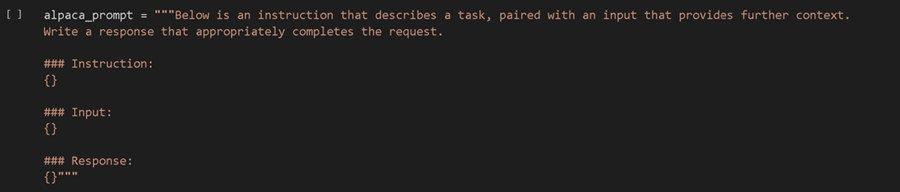
我们现在可以指定聊天模板来微调自身。非常著名的 Alpaca 格式如下:
但还记得我们说过这是一个坏主意,因为 ChatGPT 样式的微调只需要 1 个提示吗?由于我们成功地使用 Unsloth 将所有数据集列合并为 1 个,我们基本上可以创建以下样式的聊天模板,其中包含 1 个输入列(指令)和 1 个输出:
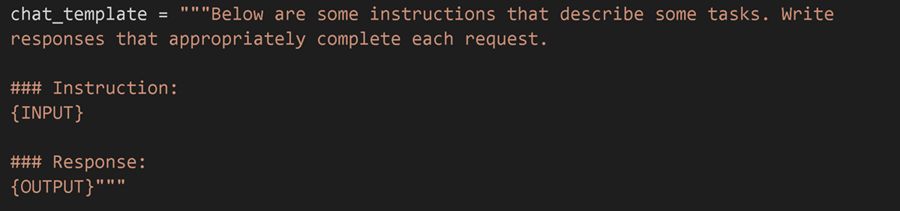
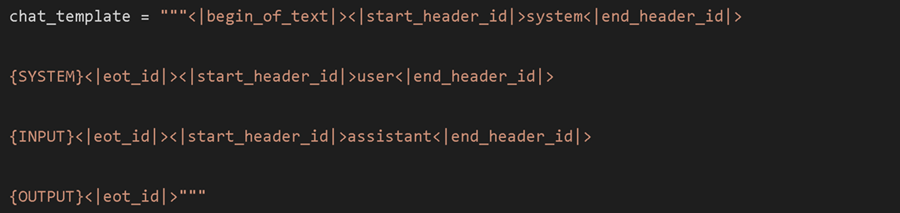
我们只要求你必须为指令放置一个 {INPUT} 字段,为模型的输出字段放置一个 {OUTPUT} 字段。事实上,我们也允许一个可选的 {SYSTEM} 字段,这对于自定义系统提示很有用,就像在 ChatGPT 中一样。例如,下面是一些很酷的例子,你可以自定义聊天模板:

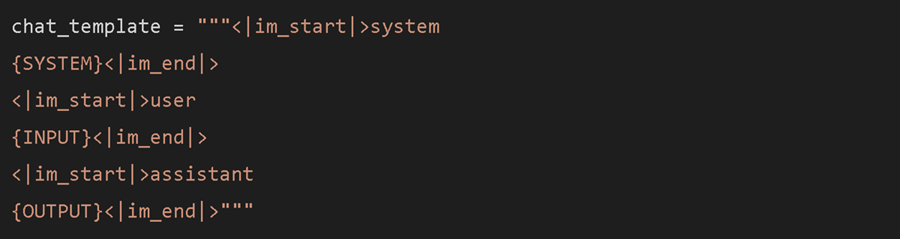
对于 OpenAI 模型中使用的 ChatML 格式:
或者你可以使用 Llama-3 模板本身(仅通过使用 Llama-3 的指令版本才能运行):我们实际上也允许一个可选的 {SYSTEM} 字段,这对于自定义系统提示很有用,就像在 ChatGPT 中一样。
或者在泰坦尼克号预测任务中,你必须预测乘客是死亡还是幸存,这个 Colab 笔记本包括 CSV 和 Excel 上传。
10、训练模型
现在让我们训练模型!我们通常建议人们不要编辑以下内容,除非你想微调更长的步骤或想要在大批量上进行训练。
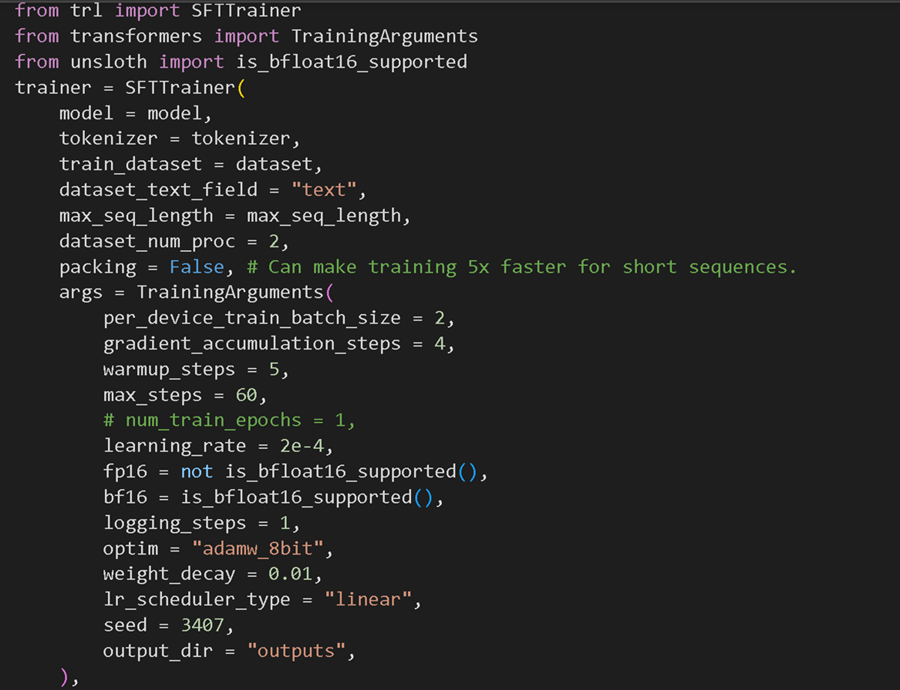
我们通常不建议更改上述参数,但要详细说明其中一些参数:
per_device_train_batch_size = 2,如果你想更多地利用 GPU 的内存,请增加批大小。同时增加此值以使训练更加流畅,并使过程不会过度拟合。我们通常不建议这样做,因为这可能会由于填充问题而使训练实际上变慢。我们通常会要求你增加 gradient_accumulation_steps,这只会对数据集进行更多遍历。
gradient_accumulation_steps = 4,相当于将批大小增加到其自身之上,但不会影响内存消耗!如果您想要更平滑的训练损失曲线,我们通常建议人们增加此值。
max_steps = 60,# num_train_epochs = 1,我们将步骤设置为 60 以加快训练速度。对于可能需要数小时的完整训练运行,请注释掉 max_steps,并将其替换为 num_train_epochs = 1。将其设置为 1 表示对数据集进行 1 次完整传递。我们通常建议传递 1 到 3 次,不要更多,否则您的微调会过度拟合。
learning_rate = 2e-4,如果你想使微调过程变慢,但也很可能会收敛到更高精度的结果,请降低学习率。我们通常建议尝试 2e-4、1e-4、5e-5、2e-5 作为数字。
你将看到一些数字的对数!这是训练损失,你的工作是设置参数以使其尽可能接近 0.5!如果你的微调未达到 1、0.8 或 0.5,你可能需要调整一些数字。如果你的损失变为 0,那可能也不是一个好兆头!
11、推理/运行模型
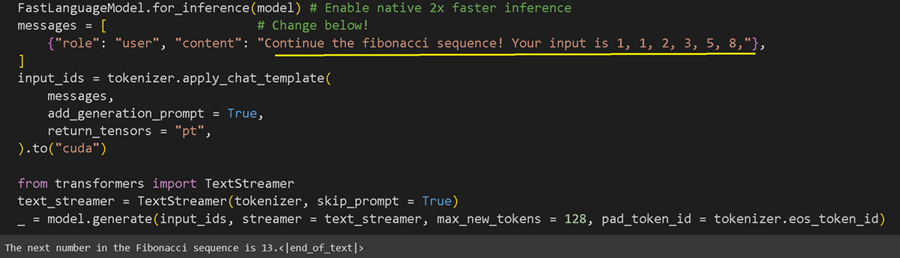
现在让我们在完成训练过程后运行模型!你可以编辑黄色下划线部分!事实上,因为我们创建了一个多轮聊天机器人,我们现在也可以调用模型,就好像它看到了过去的一些对话一样,如下所示:
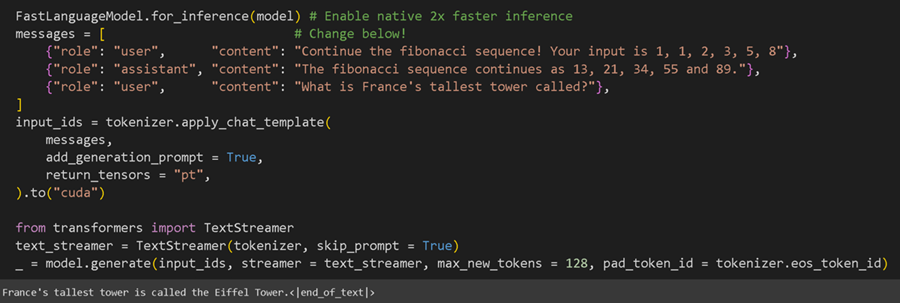
提醒 Unsloth 本身也提供了 2 倍更快的推理速度,所以永远不要忘记调用 FastLanguageModel.for_inference(model)。如果你希望模型输出更长的响应,请将 max_new_tokens = 128 设置为更大的数字,如 256 或 1024。请注意,您也需要等待更长时间才能得到结果!
12、保存模型
我们现在可以将微调后的模型保存为一个名为 LoRA 适配器的 100MB 小文件,如下所示。如果你想上传模型,也可以将其推送到 Hugging Face 中心!记得获取 Hugging Face 令牌并添加你的令牌!

保存模型后,我们可以再次使用 Unsloth 来运行模型本身!再次使用 FastLanguageModel 调用它进行推理!

13、导出到 Ollama
最后,我们可以将经过微调的模型导出到 Ollama 本身!首先,我们必须在 Colab 笔记本中安装 Ollama:
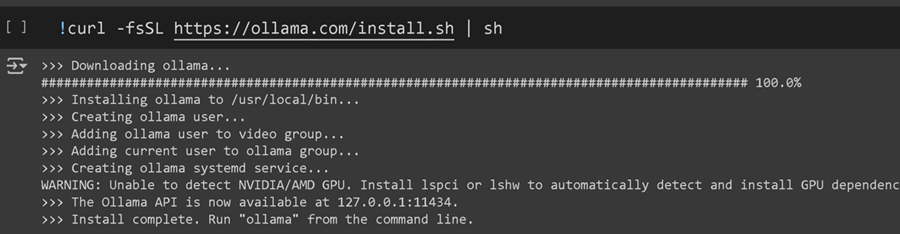
然后,我们将经过微调的模型导出为 llama.cpp 的 GGUF 格式,如下所示:
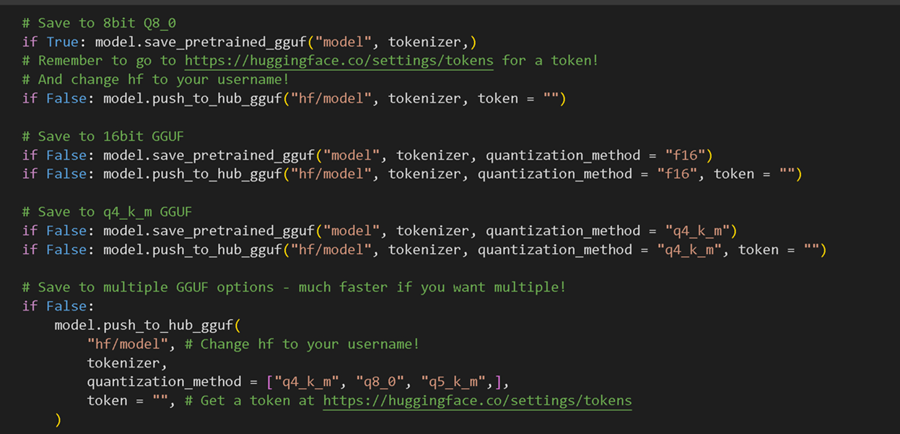
提醒将 1 行的 False 转换为 True,而不是将每一行都更改为 True,否则您将等待很长时间!我们通常建议将第一行设置为 True,这样我们就可以快速将经过微调的模型导出为 Q8_0 格式(8 位量化)。我们还允许您导出到整个量化方法列表,其中一种流行的方法是 q4_k_m。
前往这里了解有关 GGUF 的更多信息。如果你需要,我们这里还有一些关于如何导出到 GGUF 的手动说明。
你将看到一长串文本,如下所示 - 请等待 5 到 10 分钟!!
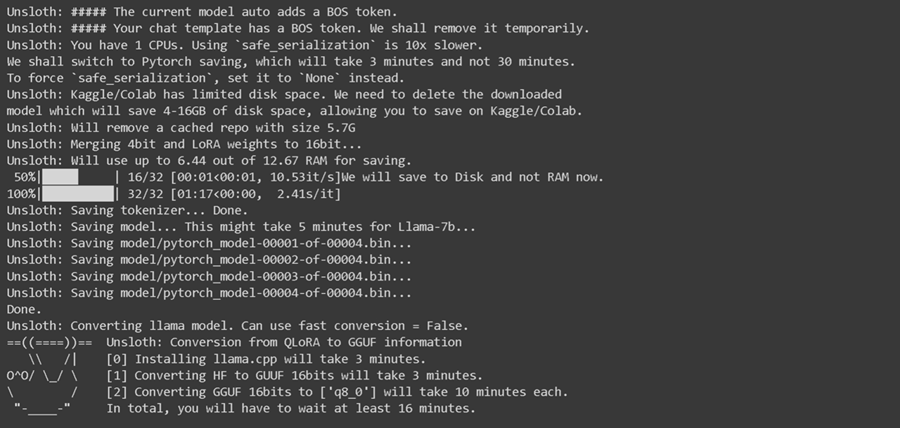
最后,它将如下所示:
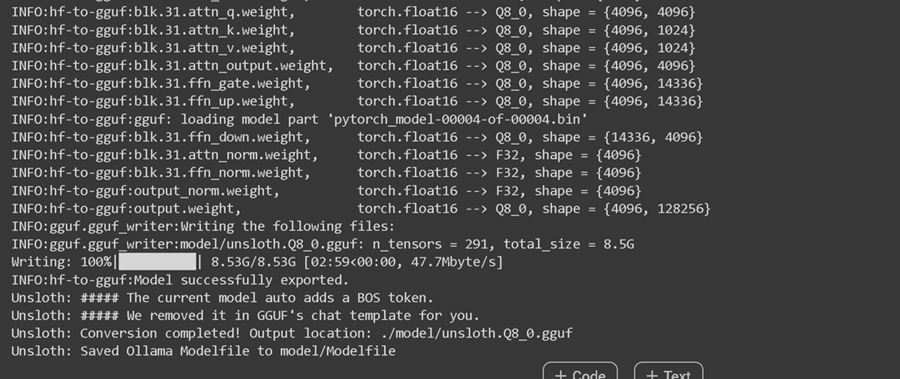
然后,我们必须在后台运行 Ollama 本身。我们使用 subprocess,因为 Colab 不喜欢异步调用,但通常只需在终端/命令提示符中运行 ollama serve。

14、自动创建模型文件
Unsloth 提供的技巧是我们自动创建 Ollama 所需的模型文件!这只是一个设置列表,其中包括我们用于微调过程的聊天模板!您还可以打印生成的模型文件,如下所示:

然后,我们要求 Ollama 使用 modelfile 创建一个与 Ollama 兼容的模型

15、Ollama 推理
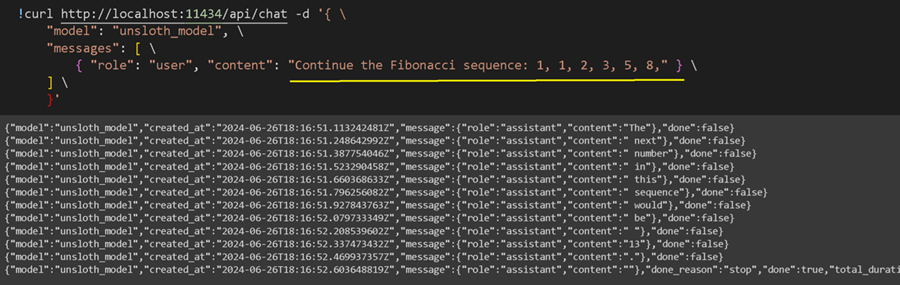
如果你想调用在您自己的本地机器上/在后台的免费 Colab 笔记本中运行的 Ollama 服务器本身,我们现在可以调用该模型进行推理。请记住,你可以编辑黄色下划线部分。
16、交互式 ChatGPT 风格
但要真正像 ChatGPT 一样运行经过微调的模型,我们还需要做更多!首先单击终端图标,将弹出一个终端。它在左侧边栏上。
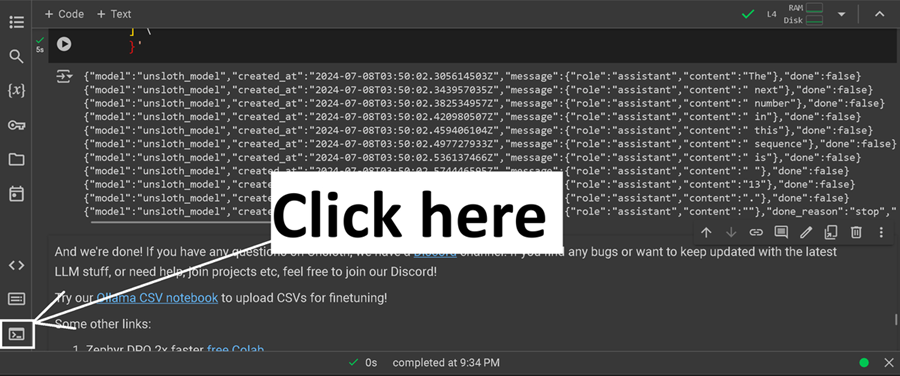
然后,你可能需要按两次 ENTER 来删除终端窗口中的一些奇怪输出。等待几秒钟,输入 ollama run unsloth_model,然后按 ENTER。

最后,你可以像实际的 ChatGPT 一样与微调后的模型进行交互!按 CTRL + D 退出系统,按 ENTER 与聊天机器人交谈!
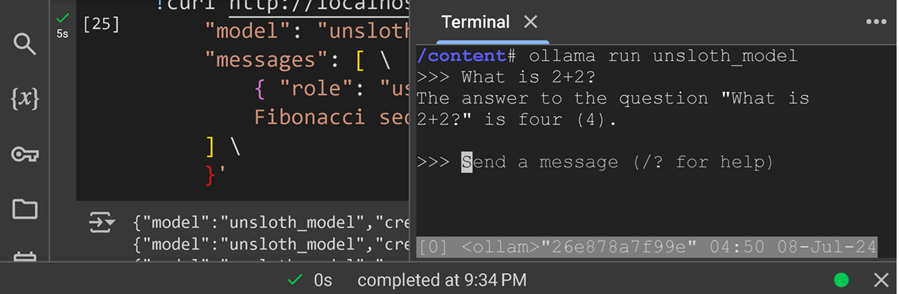
17、成功了!
你已成功微调语言模型并将其导出到 Ollama,Unsloth 速度提高了 2 倍,VRAM 减少了 70%!所有这些都可以在 Google Colab 笔记本中免费获得!
如果想学习如何进行奖励建模、进行持续预训练、导出到 vLLM 或 GGUF、进行文本补全或了解有关微调技巧的更多信息,请前往我们的 Github。
要访问我们的 Alpaca 数据集示例,请单击此处,我们的 CSV / Excel 微调指南在此处。
原文链接:How to Finetune Llama-3 and Export to Ollama
BimAnt翻译整理,转载请标明出处





