
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在阅读有关机器学习的内容时,你遇到的大部分材料可能都与分类问题有关。 你有一个特定的输入,ML 模型试图找出该输入的特征。 例如,分类模型可以决定图像中是否包含猫。
当你想创建具有预定义特征的数据时,反过来又如何呢? 这些问题可以通过生成式模型来解决,但是,从本质上讲,它们更加复杂。 两种主要方法是生成对抗网络 (GAN) 和变分自动编码器 (VAE)。 我们在最近的一篇文章中介绍了 GAN,您可以在此处找到该文章。 今天我们将分解 VAE 并理解它们背后的直觉。
1、什么是自动编码器?
我们将从解释基本自动编码器 (AutoEncoder) 的一般工作原理开始。 在构建任何 ML 模型时,你的输入都会被编码器转换为数字表示形式,供网络使用。 这样做是为了简化数据并保存其最重要的特征。 好吧,AE 只是两个网络放在一起——一个编码器和一个解码器。 这对的目标是尽可能准确地重建输入。 编码器保存输入的表示,之后解码器从该表示构建输出。
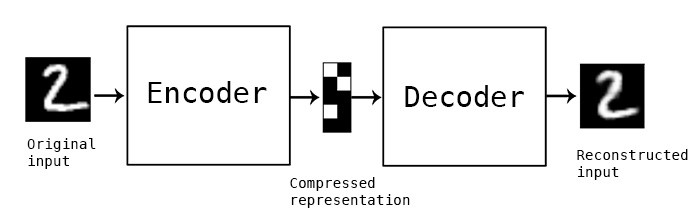
起初,这似乎有点适得其反。 为什么要经历所有以纯净、未更改的形式重建已有数据的麻烦? 关键是,通过训练过程,AE 学会构建紧凑而准确的数据表示。 它找出输入的哪些特征是定义性的并且值得保留。
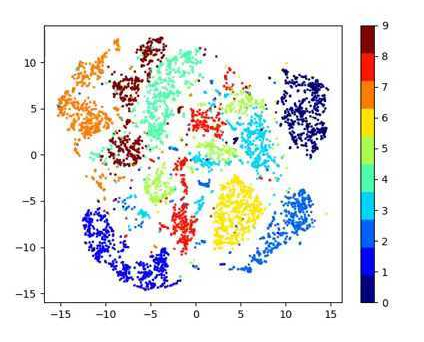
然而,除了去噪等少数应用外,AE 的使用受到限制。 它们出于生成目的的主要问题归结为他们的潜在空间的结构方式。 它不是连续的,不允许简单的外推。 编码向量被分组在对应于不同数据类的集群中,并且集群之间存在很大的差距。 为什么这是个问题? 当生成一个全新的样本时,解码器需要从潜在空间中随机抽取一个样本并进行解码。 如果潜在空间中的选定点不包含任何数据,则输出将是乱码。
2、变分自动编码器
变分自动编码器(Varational AutoEncoder)以一种特定的方式设计来解决这个问题——它们的潜在空间被构建为连续和紧凑的。 在编码过程中,标准 AE 为每个表示生成一个大小为 N 的向量。 一个输入——一个对应的向量,就是这样。 另一方面,VAE 产生 2 个向量——一个用于平均值,一个用于标准差。 VAE 不是潜在空间中的单个点,而是覆盖以平均值为中心的某个“区域”,其大小对应于标准差。 这为我们的解码器提供了更多的工作空间——来自该区域任何地方的样本将与原始输入非常相似。
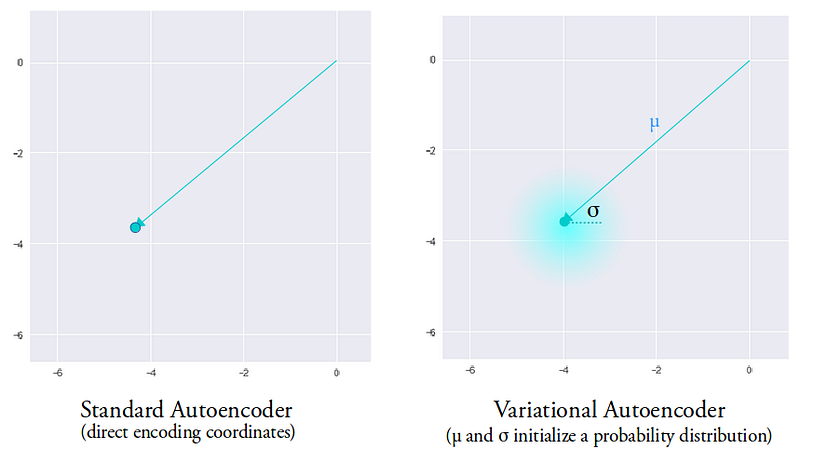
这给了我们局部范围内的可变性。 但是,我们仍然存在将数据分组到集群之间存在较大差距的问题。 为了解决这个问题,我们需要让我们所有的“区域”彼此更接近。 距离足够远以使其不同,但又足够近以允许在不同集群之间轻松进行插值。 这是通过将 Kullback-Leibler 散度添加到损失函数中来实现的。
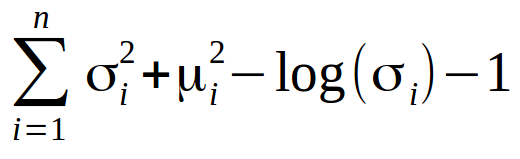
KL散度是衡量两个概率分布彼此“不同”程度的一种方式。 通过最小化它,分布将更接近潜在空间的原点。
将 Kullback-Leibler 散度与我们现有的损失函数相结合,我们激励 VAE 构建一个为我们的目的而设计的潜在空间。 数据仍然会根据不同的类别进行聚类,但聚类都将靠近潜在空间的中心。 现在我们可以自由地在潜在空间中选择随机点,以便在类之间进行平滑插值。

3、生成新数据
创建平滑的插值实际上是一个简单的过程,归结为进行向量运算。 假设你想混合两种音乐类型——古典音乐和摇滚音乐。 一旦你的 VAE 建立了它的潜在空间,你可以简单地从每个相应的集群中获取一个向量,找到它们的差异,并将该差异的一半添加到原始向量中。 解码结果后,你将获得一首新音乐! 而且由于潜在空间的连续性,我们保证解码器会有一些东西可以使用。
这也可以应用于生成和存储特定特征。 假设你有一个戴眼镜的人的图像,一个不戴眼镜的人的图像。 如果你发现它们的编码之间存在差异,你将获得一个“眼镜矢量”,然后可以将其存储并添加到其他图像中。 很棒的是,这适用于不同类别的数据,甚至是 GAN 无法处理的顺序和离散数据,例如文本。
4、用于异常检测的 VAE
除了生成新的音乐类型之外,VAE 还可以用于检测异常。 异常是指数据与其他数据的偏差足以引起人们怀疑它们是由不同来源引起的。 异常检测应用于网络入侵检测、信用卡欺诈检测、传感器网络故障检测、医疗诊断等众多领域。 如果你有兴趣了解有关异常检测的更多信息,我们将在本文中深入讨论各种方法和应用程序。
传统的 AE 可用于基于重建误差检测异常。 最初,AE 在正常数据上以半监督方式进行训练。 一旦训练完成并且 AE 收到其输入异常,解码器将无法重新创建它,因为它以前从未遇到过类似的事情。 这将导致可以检测到的大重建错误。
对于 VAE,过程是相似的,只是术语转换为概率。 最初,VAE 在正常数据上进行训练。 为了进行测试,从经过训练的 VAE 的概率编码器中抽取了几个样本。 然后,对于来自编码器的每个样本,概率解码器输出均值和标准差参数。 使用这些参数,可以计算数据源自分布的概率。 然后将平均概率用作异常分数,称为重建概率。 具有高重建概率的数据点被归类为异常。
与传统 AE 相比,VAE 的一个主要优势是使用概率来检测异常。 重建错误更难应用,因为没有通用的方法来建立清晰客观的阈值。 有了概率,即使是异构数据也可以一致地评估结果,从而使对异常的最终判断更加客观。
原文链接:The Intuition Behind Variational Autoencoders
BimAnt翻译整理,转载请标明出处





