
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在机器学习实验领域,调整超参数类似于微调复杂机器的旋钮和刻度盘。这些参数通常很微妙但至关重要,能够显著影响我们模型的性能和行为。WandB(权重和偏差 ) 是一个强大的在线工具集,旨在简化模型训练、评估和分析的过程。
随着我们开始探索,我们将揭示超参数的本质,这些关键变量决定了我们的机器学习模型的行为和功效。通过 wandb 的视角,我们将深入研究跟踪这些参数、可视化模型性能以及将实验无缝集成到我们的工作流程中的艺术。加入我们,揭开超参数管理的复杂性,为充分利用 wandb 在机器学习方面的潜力奠定基础。
1、环境准备
首先我们需要在wandb上建立一个简单的设置,以帮助我们监控模型性能。为此,我们需要首先在wandb上创建用户登录凭据。
创建一组登录凭据后,你需要获取 API 登录密钥,该密钥将位于你的“用户设置”中。接下来,需要使用以下命令安装 wandb API:
pip install wandb接下来你将使用以下命令:
wandb login并提供 API 密钥和登录用户名。
2、测试问题
现在我们将制作一个简单的深度学习模型,我们的 wandb 应用程序将集成到该模型中。对于本文,我决定在 TensorFlow 中训练一个模型,该模型将检测某人是否在微笑。这是一个简单的两类分类问题。
我们首先从导入必要的库开始:
import tensorflow as tf
from keras import layers
import matplotlib.pyplot as plt
import keras
from sklearn.metrics import accuracy_score, confusion_matrix, roc_curve, auc
import seaborn as sns
from keras.models import Sequential, load_model
from keras.layers import Dense, Activation, Dropout, Flatten, Conv2D, MaxPooling2D
from keras.layers import BatchNormalization
from keras.callbacks import ModelCheckpoint, LearningRateScheduler
import wandb
import h5py, os
import numpy as np
from wandb.keras import WandbCallback接下来,我们将初始化 wandb API 并在其中创建我们的项目。此项目标题将帮助我们将其他项目区分开来。对于本文,项目名称将是“smile-no-smile”:
wandb.init(project="smile-no-smile")完成后,我们将进行初始数据加载和预处理阶段:
path_to_train = "Data/happy/train_happy.h5/train_happy.h5"
path_to_test = "Data/happy/test_happy.h5/test_happy.h5"
### check and load the data
if not os.path.exists(path_to_train):
raise ValueError("Can't find the train dataset")
else:
train_dataset = h5py.File(path_to_train, "r")
test_dataset = h5py.File(path_to_test, "r")
# Normalize the images
train_x = train_dataset["train_set_x"][:] / 255.
test_x = test_dataset["test_set_x"][:] / 255.
# Get the labels
train_y = train_dataset["train_set_y"][:]
test_y = test_dataset["test_set_y"][:]
# We will also split the train set into train and validation set
from sklearn.model_selection import train_test_split
train_x, val_x, train_y, val_y = train_test_split(train_x, train_y, test_size=0.2, random_state=42)为了可视化我们的数据,我们将绘制图像及其各自的标签,如下所示:
### we use matplotlib to plot sample images for each class
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
plt.figure(figsize=(10,10))
for i in range(5):
plt.subplot(1,5,i+1)
plt.imshow(train_dataset["train_set_x"][i])
plt.axis("off")
plt.title("Label: " + str(train_dataset["train_set_y"][i]))
plt.show()这将得到如下输出:

为了训练模型,我们还将对图像进行一些预处理和增强,以便更好地训练模型。我们可以使用 keras 制作一个简单的数据增强管道,它将是位于模型的输入和内部层之间的一层。实际上,它看起来像这样:
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomZoom(0.2),
layers.RandomContrast(0.3),
layers.RandomBrightness(0.3),
]
)
### Model with data augmentaion pipeline ###
inputs = keras.Input(shape=(64, 64, 3))
x = data_augmentation(inputs)
x = layers.Conv2D(filters=32, kernel_size=5, activation="relu")(inputs)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Conv2D(filters=32, kernel_size=3, activation="relu")(x)
x = layers.MaxPooling2D(pool_size=2)(x)
x = layers.Flatten()(x)
x = layers.Dense(256, activation="relu")(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs=inputs, outputs=outputs)如我们所见,代码中已经包含了数据增强部分。
现在对于训练部分,我们还可以实施一些不同的技术来帮助模型更快地达到局部最小值。其中一种方法是使用衰减学习率。这也有一些额外的好处,例如:
- 更快地达到最小值
- 在达到更高的准确度之前降低模型停滞的风险。
- 获得更好的整体学习
为此,我们将定义一个函数,该函数将使用 keras.callbacks 根据时期动态更新学习率,即它将从较高的学习率开始,并在接近最终时期时不断降低学习率。
def step_decay(epoch):
initial_lr = 0.001 # Initial learning rate
drop = 0.5 # Learning rate drop factor
epochs_drop = 5 # Number of epochs after which learning rate will drop
new_lr = initial_lr * (drop ** (epoch // epochs_drop))
return new_lr
### call the method step_decay() using keras learningRateScheduler method
lr_scheduler_exponential_decay = LearningRateScheduler(step_decay)最后,我们将编译模型并有一个检查点回调,它将从模型停止训练的时间点加载并继续训练过程:
modelName = "happ-sadM.h5"
try:
model = load_model(modelName)
print("Loaded model from disk")
except:
print("No model found, creating new one")
checkpoint = ModelCheckpoint(
'happ-sadM.h5', monitor='val_loss', save_best_only=True)
### we will now compile the model
model.compile(optimizer='adam',
loss="binary_crossentropy",
metrics=['accuracy'])3、WandB API 和指标
现在我们的模型已准备好进行训练和测试,我们将设置所有回调并将其连接到 WandB API,并查看 API 能够捕获的各种见解。
history = model.fit(train_x, train_y, epochs=40,
validation_data=(val_x, val_y),
callbacks=[checkpoint, lr_scheduler_exponential_decay, WandbCallback()])WandbCallback() 方法将为我们处理大部分指标捕获。但是,如果我们想添加一些其他信息,例如混淆矩阵或准确度分数,我们可以使用 wandb.log() 来实现相同的目的。
例如,我们可以将以下代码片段添加到上面的代码中:
preds = model.predict(test_x)
preds = np.round(preds).astype(int).reshape(1, -1)[0]
fpr, tpr, thresholds = roc_curve(test_y, preds)
roc_auc = auc(fpr, tpr)
wandb.log({'accuracy': accuracy_score(test_y, preds), "roc_curve": wandb.Image(plt)})通过使用 wandb.log(),我们可以将某些输出(如图表)添加为图像,我们可以在 wandb 仪表板上看到这些图像:
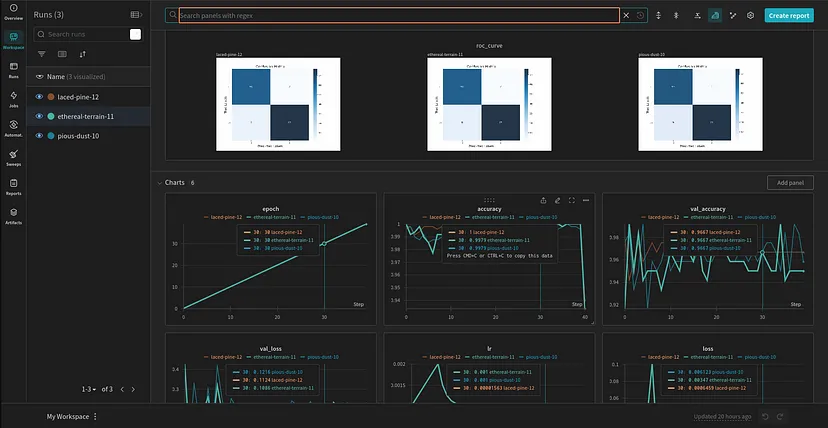
如我们所见,我们的仪表板将提供对模型进行完整评估所需的所有指标,同时还将提供 GPU 利用率,这在云资源上训练大型模型时非常有用。
4、结束语
从这篇文章中,我们能够评估一个简单的模型并提供必要的详细信息。在下一篇文章中,我们将使用 wandb 工具集中的 Sweep 方法来找到我们模型的最佳参数集。
原文链接:Intro to WandB (Weights and Biases) a tool for hyperparameter tuning (Part 1)
BimAnt翻译整理,转载请标明出处





