
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
LLM的未来是边缘计算、无处不在的部署和深度个性化。 这就需要 LLM 技术的民主化,而它离不开 ReAct 范式。
成本必须下降。 一项关键技术是检索增强生成(RAG),它可以使LLM个性化,而无需昂贵的训练过程(“微调”)。
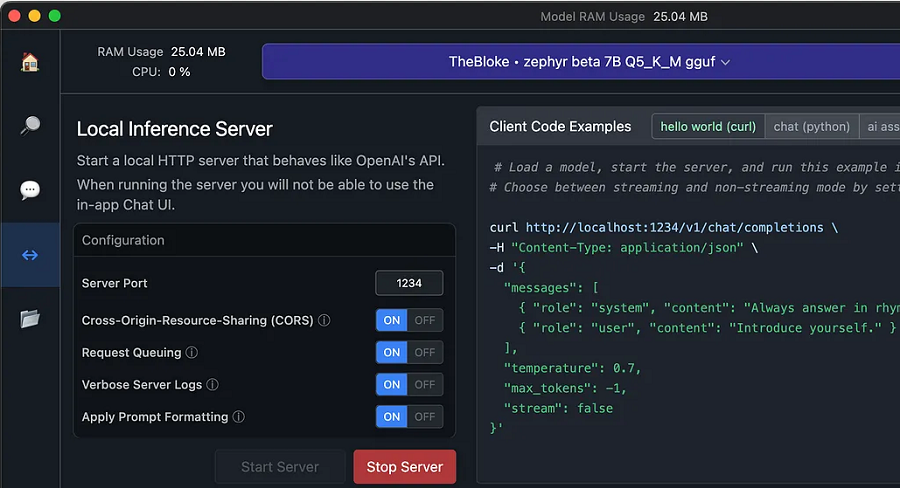
1、自托管LLM
大型语言模型 (LLM) 了解很多,但对你一无所知(除非你很出名)。 这是因为他们接受了公共数据集的训练,而您的私人信息(希望)不是公开的。
我们在这里讨论的是敏感数据:银行对账单、个人日记、浏览器历史记录等。请说我是偏执狂,但我不想通过互联网将这些数据发送到云中托管的LLM,即使我支付了一大笔费用 让他们成为好知己。 我想在本地运行LLM。
许多LLM都是免费提供的,因此您可以离线托管它们。 仅举几例:Llama、Alpaca、Sentret、Mistral、Jynx 和 Zephyr。 事实上,有太多的选择让你无法追踪它们——证据:其中两个是神奇宝贝,而你甚至没有注意到。
2、让 LLM 了解你
为了使LLM与你相关,直觉可能是根据你的数据对其进行微调,但是:
- 训练LLM的费用很高。
- 由于训练成本的原因,很难用最新信息更新LLM。
- 缺乏可观察性。 当你向LLM提出问题时,LLM如何得出答案并不明显。
有一种不同的方法:检索增强生成(RAG)。 像 LlamaIndex 这样的框架不会要求 LLM 立即生成答案:
- 首先从你的数据源检索信息,
- 将其作为上下文添加到你的问题中,并且
- 要求LLM根据丰富的提示进行回答。
RAG 克服了微调方法的所有三个弱点:
- 不需要训练,所以很便宜。
- 仅当你请求数据时才会获取数据,因此数据始终是最新的。
- 该框架可以向你显示检索到的文档,因此更值得信赖。
RAG 对你使用LLM的方式几乎没有限制。 仍然可以将LLM用作自动完成、聊天机器人、半自主代理等。 它只会让LLM与你更相关。
RAG 是经过实战考验的。 Microsoft-OpenAI 在这场比赛中遥遥领先。 在企业方面,Azure 添加了一项名为 GPT-RAG 的功能。 在消费者方面,Bing Chat 是良好 RAG 实现的教科书示例,GPT-4 及其函数调用功能也是如此。
3、拥有 RAG 的LLM是智能体
函数调用在这里值得一提,尽管它超出了 RAG 文章的范围。
在 RAG 中,检索操作必须以某种方式执行。 因此,它是一个函数。 函数不必是纯函数(在数学意义上); 也就是说,它们可能会产生副作用(在编程世界中,它们经常会产生副作用)。 因此,函数只是LLM可以运用的工具。 打个比方,我们将那些具有工具使用能力的LLM称为智能体(Agent)。
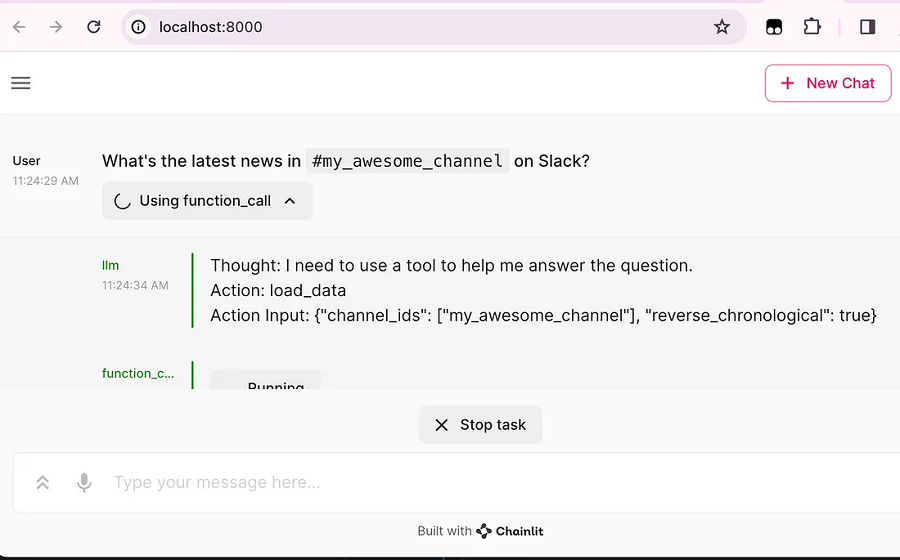
GPT-4 并不是唯一可以调用函数的模型; 普通LLM可以通过名为ReAct的范式成为智能体。 简而言之,与其要求LLM立即回答你的问题(或回应你的需求),不如:
- 向LLM介绍了可以使用的工具列表,
- 询问LLM希望使用哪种工具(以及如何)来获取自信地回答你的问题(或执行满足你需求的任务)所需的信息,
- 运行相应的函数,
- 将工具执行的结果反馈给LLM,就像你自己使用了该工具,观察了结果,并向LLM描述了你所看到的情况,
- 询问 LLM 是否已获得完成查询所需的全部内容,以及
- 如果是这样,最后要求它回答你的问题; 否则,返回步骤 2。
ReAct 使LLM的智能体民主化。 ReAct 范式使用纯粹的语义方法,使并非设计用于连接程序的模型能够这样做。 它为那些自行托管大型语言模型的人创造了巨大的可能性。
4、结束语
RAG 和 ReAct 是两个(嵌套的)概念,它们是民主化人工智能技术的未来。 我对 LlamaIndex 等开源项目的增长充满信心。 如果你也相信边缘计算LLM的未来将无处不在,请加入我们的旅程。
原文链接:Why RAG is big
BimAnt翻译整理,转载请标明出处





