
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
经过几个月的寻找,你终于找到了。
唯一可以正常工作的对象检测库。 没有安装麻烦,没有软件包版本不匹配,也没有 CUDA 错误。
我说的是 Ultralytics 精心设计的 YOLOv5 目标检测库。
你很高兴,很快就从 Roboflow 找到了一个有趣的数据集,并最终训练了一个最先进的 (SOTA) YOLOv5 模型来从图像流中检测枪支。
你浏览了一份快速清单 –
- 推理结果,已检查 ✅
- COCO mAP,已检查 ✅
- 实时推理延迟,已检查 ✅
你站在世界之巅。

终于可以在下周一向客户展示结果。 在你的脑海中,已经可以看到客户对这一惊人壮举印象深刻的表情。
在展示的日子里,当你认为事情正在朝着正确的方向发展时。 一位客户问道,
“你的模型可以在我们现有的 CPU 上运行吗?”
你退缩了。
这不是你所预料到的。 你试图让他们相信 GPU 是“前进的方向”,并且是实时运行模型的“最佳方式”。
你扫视了整个房间,并开始注意到每次你说 GPU 和 CPU 这个词时他们脸上的表情。

不用说,进展并不顺利。 我希望没有人会在投球过程中遇到这种尴尬的情况。 你不必像我一样通过艰难的方式来学习它。
你可能想知道,我们真的可以使用消费级 CPU 来实时运行模型吗?
🦾是的,我们可以!
我以前不是信徒,但在发现Neural Magic之后,现在我是信徒了。
在这篇文章中,我将向你展示如何使用 Neural Magic 的免费开源工具增强在 CPU 上运行的 YOLOv5 推理性能。
如果这听起来令人兴奋,让我们开始吧 🧙
1、🔩 环境搭建
1.1 🔫 数据集
最近的枪支暴力新闻让我深入思考如何才能防止此类事件再次发生。 这是自2012年以来最严重的枪支暴力事件,造成21名无辜者丧生。
我深感悲痛,我的心与所有暴力受害者及其亲人同在。
我不是立法者,所以我无能为力。 但是,我想我在计算机视觉方面了解一些可能会有所帮助的东西。 就在那时,我发现了 Roboflow 的手枪数据集。
该数据集包含单标注(手枪)的 2986 个图像和 3448 个标签。 图像范围广泛:手中的手枪、卡通以及演播室品质的枪支图像。 该数据集最初由格林纳达大学发布。

1.2 🦸 安装
现在我们先将下载的 Pistols 数据集放入相应的文件夹中。 我会将下载的图像和标签放入 datasets/ 文件夹中。
我们还将 SparseML 中的稀疏化配方放入recipes/文件夹中。 稍后详细介绍配方。
这是我的目录的高级概述。
├── req.txt
├── datasets
│ ├── pistols
│ │ ├── train
| | ├── valid
├── recipes
│ ├── yolov5s.pruned.md
│ ├── yolov5.transfer_learn_pruned.md
│ ├── yolov5.transfer_learn_pruned_quantized.md
| └── ...
└── yolov5-train
├── data
| ├── hyps
| | ├── hyps.scratch.yaml
| | └── ...
| ├── pistols.yaml
| └── ...
├── models_v5.0
| ├── yolov5s.yaml
| └── ...
├── train.py
├── export.py
├── annotate.py
└── ...在这篇文章中,我们将使用 YOLOv5 库的分叉版本,它允许我们在接下来的部分中进行自定义优化。
要安装本博客文章中的所有软件包,请运行以下命令
git clone https://github.com/dnth/yolov5-deepsparse-blogpost
cd yolov5-deepsparse-blogpost/
pip install torch==1.9.0 torchvision==0.10.0 --extra-index-url https://download.pytorch.org/whl/cu111
pip install -r req.txt2、⛳ 基准性能
2.1 🔦PyTorch
现在一切就绪,让我们开始训练一个没有优化的基线模型。
为此,运行 yolov5-train/ 文件夹中的 train.py 脚本。
python train.py --cfg ./models_v5.0/yolov5s.yaml \
--data pistols.yaml \
--hyp data/hyps/hyp.scratch.yaml \
--weights yolov5s.pt --img 416 --batch-size 64 \
--optimizer SGD --epochs 240 \
--project yolov5-deepsparse --name yolov5s-sgd选项说明如下:
--cfg – Path to the configuration file which stores the model architecture.
--data – Path to the .yaml file that stores the details of the Pistols dataset.
--hyp – Path to the .yaml file that stores the training hyperparameter configurations.
--weights – Path to a pretrained weight.
--img – Input image size.
--batch-size – Batch size used in training.
--optimizer – Type of optimizer. Options include SGD, Adam, AdamW.
--epochs – Number of training epochs.
--project – Wandb project name.
--name – Wandb run id.所有指标都记录到此处的权重和偏差 (Wandb)。
训练完成后,让我们使用 annotate.py 脚本对视频进行推理。
python annotate.py yolov5-deepsparse/yolov5s-sgd/weights/best.pt \
--source data/pexels-cottonbro-8717592.mp4 \
--engine torch \
--image-shape 416 416 \
--device cpu \
--conf-thres 0.7第一个参数指向 .pt 保存的检查点。
--source - 运行推理的输入。 选项:视频/图像的路径或仅指定 0 以根据您的网络摄像头进行推断。
--engine - 使用哪个引擎。 选项:torch、deepsparse、onnxruntime。
--image-size – 输入分辨率。
--device – 用于推理的设备。 选项:cpu 或 0 (GPU)。
--conf-thres – 推理的置信度阈值。注意:推理输出将保存在annotation_results/文件夹中。
以下是在使用全部 8 个 CPU 内核的 Intel i9-11900 上运行基准 YOLOv5-S 的情况。

- 平均帧率:21.91
- 平均推理时间(毫秒):45.58
实际上,FPS 看起来已经相当不错,即使没有进一步优化也可能适合某些应用程序。
但当你能得到更好的东西时,为什么还要安定下来呢? 毕竟,这就是你来这里的原因,对吧? 😉
让我们继续👇
2.2 🕸 DeepSparse引擎
DeepSparse 是 Neural Magic 的推理引擎,可在 CPU 上最佳运行。 它非常容易使用。 只需给它一个 ONNX 模型,你就可以开始使用了。
让我们使用 export.py 脚本将 .pt 文件导出到 ONNX 中。
python export.py --weights yolov5-deepsparse/yolov5s-sgd/weights/best.pt \
--include onnx \
--imgsz 416 \
--dynamic \
--simplify选项说明如下:
--weight – .pt 检查点的路径。
--include – 导出为哪种格式。 选项:torchscript、onnx 等。
--imgsz – 图像大小。
--dynamic – 动态轴。
--simplify – 简化 ONNX 模型。现在,再次运行推理脚本,这次使用 deepsparse 引擎,并且 --num-cores 参数中仅使用 4 个 CPU 核心。
python annotate.py yolov5-deepsparse/yolov5s-sgd/weights/best.onnx \
--source data/pexels-cottonbro-8717592.mp4 \
--image-shape 416 416 \
--conf-thres 0.7 \
--engine deepsparse \
--device cpu \
--num-cores 4
- 平均帧率:29.48
- 平均推理时间(毫秒):33.91
就这样,我们将平均 FPS 从 21+(使用 8 核的 CPU 上的 PyTorch 引擎)提高到 29+ FPS。 我们所做的就是使用带有 DeepSparse 引擎的 ONNX 模型。
P/S:我们已经完成了这里的基线! 真正的行动只会在接下来发生 - 当我们使用 👇 运行稀疏化时
3、👨🍳 SparseML 和配方
稀疏化是从模型中删除冗余信息的过程。 结果是一个更小、更快的模型。
这就是我们如何大幅加快 YOLOv5 模型的速度!
我们如何稀疏模型?
使用 SparseML - Neural Magic 的开源库。 借助 SparseML,可以通过将预制配方应用于模型来稀疏神经网络。 还可以修改配方以满足你的需要。
你可能会想,这听起来好得令人难以置信!
有什么注意事项?
好问题!
通过稀疏化,根据稀疏化程度,可能会出现轻微的精度损失。 高度稀疏的模型通常不如原始模型准确,但速度和延迟显着提高。
使用 SparseML 的配方,精度损失范围为 2% 到 6%。 换句话说,与原始模型的性能相比,恢复率为 94% 至 98%。 作为交换,我们获得了惊人的速度提升,从 2 倍到 10 倍不等!
在大多数情况下,这没什么大不了的。 如果精度损失是你可以忍受的,那么让我们稀疏一些模型吧! 🤏。
3.1 ☝️ One-Shot
One-Shot是稀疏现有模型的最简单方法,因为它不需要重新训练。
但目前这仅适用于动态量化。 目前正在进行的工作旨在使一次性修剪更有效。
让我们在之前训练的基线模型上运行One-Shot方法。 你需要做的就是向训练脚本添加 --one-shot 参数,并指定修剪 --recipe。 请记住将 --weights 指定为训练中最佳检查点的位置。
python train.py --cfg ./models_v5.0/yolov5s.yaml \
--recipe ../recipes/yolov5s.pruned.md \
--data pistols.yaml --hyp data/hyps/hyp.scratch.yaml \
--weights yolov5-deepsparse/yolov5s-sgd/weights/best.pt \
--img 416 --batch-size 64 --optimizer SGD --epochs 240 \
--project yolov5-deepsparse --name yolov5s-sgd-one-shot \
--one-shot它应该在 --name 指定的目录中生成另一个 .pt。 此 .pt 文件以 int8 格式而不是 fp32 存储量化权重,从而减少模型大小并提高推理速度。
接下来,我们将量化的 .pt 文件导出为 ONNX 格式。
python export.py --weights yolov5-deepsparse/yolov5s-sgd-one-shot/weights/checkpoint-one-shot.pt \
--include onnx \
--imgsz 416 \
--dynamic \
--simplify并进行推理:
python annotate.py yolov5-deepsparse/yolov5s-sgd-one-shot/weights/checkpoint-one-shot.onnx \
--source data/pexels-cottonbro-8717592.mp4 \
--image-shape 416 416 \
--conf-thres 0.7 \
--engine deepsparse \
--device cpu \
--num-cores 4
- 平均帧率:32.00
- 平均推理时间(毫秒):31.24
在没有重新训练成本的情况下,我们的性能比原始模型提高了 10 FPS。 我们的最高帧速率约为 40 FPS!
One-Shot方法只需要几秒钟就可以完成。 如果你正在寻找最简单的方法来提高性能,那么One-Shot就是最佳选择。
但是,如果你愿意重新训练模型以使其性能和速度加倍,请继续阅读👇
3.2 🤹♂️ 稀疏迁移学习
使用 SparseML,你可以采用已经稀疏的模型(修剪和量化)并在自己的数据集上对其进行微调。 这称为稀疏迁移学习。
这可以通过运行以下命令来完成:
python train.py --data pistols.yaml --cfg ./models_v5.0/yolov5s.yaml
--weights zoo:cv/detection/yolov5-s/pytorch/ultralytics/coco/pruned_quant-aggressive_94?recipe_type=transfer
--img 416 --batch-size 64 --hyp data/hyps/hyp.scratch.yaml
--recipe ../recipes/yolov5.transfer_learn_pruned_quantized.md
--optimizer SGD
--project yolov5-deepsparse --name yolov5s-sgd-pruned-quantized-transfer上面的命令从 Neural Magic 的 SparseZoo 加载稀疏 YOLOv5-S 并在数据集上运行训练。
--weights 参数指向 SparseZoo 的模型。 SparseZoo 中有更多可用的稀疏模型。 我将让你探索哪种模型最有效。
使用 annotate.py 运行推理结果:

- 平均帧率:51.56
- 平均推理时间(毫秒):19.39
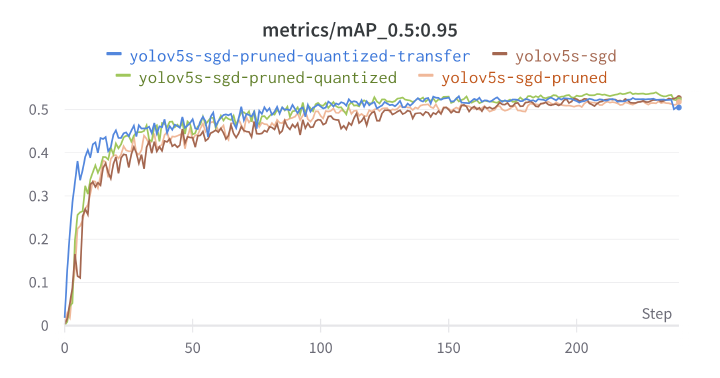
与之前的一次性方法相比,我们的 FPS 几乎提高了 2 倍! 从 FPS 值和 mAP 分数来看,稀疏迁移学习对于大多数应用程序都很有意义。
但是,如果你进一步仔细研究 Wandb 仪表板上的 mAP 指标,会发现它略低于下一个方法 💪。
3.3 ✂ 修剪后的 YOLOv5-S
在这里,我们不会采用已经稀疏的模型,而是通过自己修剪来稀疏我们的模型。
为此,我们将使用 SparseML 存储库上的预制配方。 此配方告诉训练脚本如何在训练期间修剪模型。
为此,我们稍微修改 train.py 的参数:
python train.py --cfg ./models_v5.0/yolov5s.yaml \
--recipe ../recipes/yolov5s.pruned.md
--data pistols.yaml \
--hyp data/hyps/hyp.scratch.yaml \
--weights yolov5s.pt --img 416
--batch-size 64 --optimizer SGD \
--project yolov5-deepsparse --name yolov5s-sgd-pruned这里唯一的变化是 --recipe 和 --name 参数。 此外,无需指定 --epoch 参数,因为训练纪元的数量已在配方中指定。
--recipe 告诉训练脚本 YOLOv5-S 模型使用哪个配方。 在本例中,我们使用 yolov5s.pruned.md 配方,它仅在训练时修剪模型。 你可以通过修改 yolov5s.pruned.md 配方来更改模型的修剪程度。
运行推理,我们发现:

- 平均帧率:35.50
- 平均推理时间(毫秒):31.73
与稀疏迁移学习方法相比,FPS 的下降是预料之中的,因为该模型仅进行了剪枝,并未进行量化。 但我们获得了更高的 mAP 值。
3.4 🔬 量化 YOLOv5-S
我们已经看到了剪枝的效果,那么量化呢? 让我们对 YOLOv5-S 模型进行量化,看看它的表现如何。
我们可以在没有训练的情况下运行量化(One-Shot)。 但为了获得更好的效果,我们将模型训练 2 个 epoch。 重新训练 2 个 epoch 可以让权重重新调整到量化值,从而产生更好的结果。
训练纪元数在 yolov5s.quantized.md 文件中指定。
让我们运行 train.py:
python train.py --cfg ./models_v5.0/yolov5s.yaml \
--recipe ../recipes/yolov5s.quantized.md \
--data pistols.yaml \
--hyp data/hyps/hyp.scratch.yaml \
--weights yolov5-deepsparse/yolov5s-sgd/weights/best.pt --img 416 \
--batch-size 64 --project yolov5-deepsparse --name yolov5s-sgd-quantized使用 annotate.py 进行推理:

- 平均帧率:43.29
- 平均推理时间(毫秒):23.09
与修剪后的模型相比,我们的 FPS 有所提高。 仔细观察,你会发现在 0:03 秒出现了误检测。
在这里,我们看到量化模型比修剪模型更快,但代价是检测精度下降。 但请注意,在这个模型中,我们只训练了 2 个 epoch,而剪枝模型则训练了 240 个 epoch。 更长时间的重新训练可能会解决误检测问题。
我们已经看到了 YOLOv5-S 模型在以下情况下的表现:
- 仅修剪
- 仅量化
但是,我们可以同时进行剪枝和量化吗?
当然,为什么不? 🤖
3.5 剪枝 + 量化 YOLOv5-S
现在,让我们通过运行修剪和量化将其提升到一个新的水平。 请注意区别——我正在使用的--recipe。
python train.py --cfg ./models_v5.0/yolov5s.yaml \
--recipe ../recipes/yolov5.transfer_learn_pruned_quantized.md \
--data pistols.yaml \
--hyp data/hyps/hyp.scratch.yaml \
--weights yolov5s.pt --img 416 \
--batch-size 64 --optimizer SGD \
--project yolov5-deepsparse --name yolov5s-sgd-pruned-quantized使用export.py导出并使用annotate.py运行推理。 我们得到

- 平均帧率:58.06
- 平均推理时间(毫秒):17.22
在我们的 Wandb 仪表板上,该模型得分最高,也是最快的。
它兼得了两者的优点! 🎯
我想在这里结束这篇文章。 但我仍然无法忽视这个挥之不去的想法。 它让我彻夜难眠。 所以我必须这样做🤷♂️。
每天晚上我都想知道我们在 CPU 上运行 YOLOv5 的速度有多快? 我的意思是 SparseML + DeepSparse 的最大可能 FPS。
这让我发现👇
4、🚀 为较小的模型提供增压
在 YOLOv5 系列中,YOLOv5-Nano 是最小的模型。 理论上来说,这应该是最快的。
所以我把赌注押在这个模型上。 让我们对 YOLOv5-Nano 模型再次应用相同的步骤。
。。。
🚀🚀🚀

- 平均帧率:101.52
- 平均推理时间(毫秒):9.84
🤯 这真是令人兴奋! 最大FPS达到180+范围。 我从来没有想象过这些数字是可能的,特别是仅使用 4 个 CPU 核心。
看到这里我晚上可以安心睡觉了😴
5、 🚧 结论
这是一段多么美妙的旅程啊。
我们需要 GPU 来实时运行模型的日子已经一去不复返了。 借助 DeepSparse 和 SparseML,你可以在商用 CPU 上获得 GPU 级的性能。
原文链接:Supercharging YOLOv5: How I Got 182.4 FPS Inference Without a GPU
BimAnt翻译整理,转载请标明出处





