
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
YOLOv9是YOLO系列中用于实时目标检测的最新进展,引入了可编程梯度信息(PGI)和通用高效层聚合网络(GELAN)等新技术来解决信息瓶颈并提高检测精度和效率。 在这篇文章中,我们研究了 YOLOv9 的一些关键优势。
1、什么是YOLO?
YOLO 首次出现在 Joseph Redmon 等人 2015 年的首篇论文《You Only Look Once: Unified, Real-Time Object Inspection》中。 该模型架构在目标检测的深度学习领域具有重要意义,因为它被设计为仅查看图像一次,从而将传统的预测位置和分类的两阶段过程转变为单阶段过程,其中 分类对象也与边界框映射在一起。
YOLO模型系列因其任务灵活性和模型紧凑性而在计算机视觉领域作为强大的目标检测机器学习模型而闻名,同时仍然保持最先进的性能。 这使得 YOLO 模型能够集成到许多行业垂直领域,并可供广泛的机器学习从业者使用。
其持续成功的第二个原因是它从最初的 Darknet 版本 1-4 实现过渡到更常用的 PyTorch 框架(YOLOv5、YOLOv7 和 YOLOv8)。 鉴于 PyTorch 中更强大的研究社区,YOLO 模型系列受到了极大的开发关注和快速改进。 YOLOv9 是自诞生以来多次开发迭代的结果,不断挑战目标检测领域最先进的模型架构。
2、YOLOv9 概述
YOLOv9 建立在 2022 年推出的 YOLOv7 先前成功基础上。两者均由 Chien-Yao Wang 等人开发。 YOLOv7在训练过程中重点关注架构优化,称为可训练的免费赠品袋,以加强训练成本以提高目标检测精度,但不会增加推理成本。 然而,它没有解决由于前馈过程中的各种降尺度操作而导致输入数据信息丢失的问题,这种现象称为信息瓶颈。
虽然使用可逆架构和掩模建模等现有方法已被证明可以缓解信息瓶颈,但它们似乎对更紧凑的模型架构失去了功效,而这一直是 YOLO 模型系列等实时目标检测器的标志性特征。
YOLOv9引入了两种新颖的技术,不仅解决了信息瓶颈问题,而且进一步突破了提高目标检测精度和效率的界限。
3、可编程梯度信息
YOLOv9 旨在通过称为可编程梯度信息(PGI)的辅助监督框架来解决信息瓶颈。 PGI 通常被设计为训练辅助工具,通过与先前层的互连来提高梯度反向传播的效率和准确性,但通过可移动分支,可以在推理时删除这些额外的计算,以提高模型的紧凑性和推理速度。 为了改进这些互连,它利用带有集成网络的多级辅助信息,聚合来自多个卷积阶段的梯度以合并有意义的梯度以进行传播。 PGI 由三个关键部分组成:
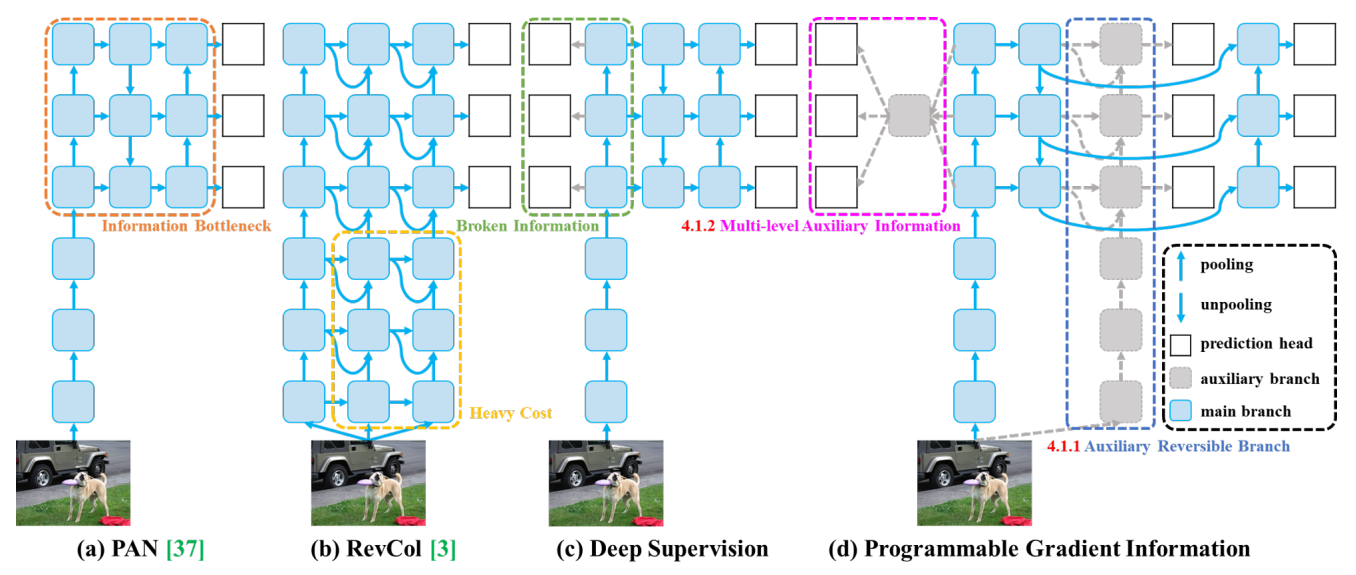
- 主分支:主分支主要用于推理过程。 由于推理阶段不需要 PGI 的其他组件,因此 YOLOv9 确保不会产生额外的推理成本。
- 辅助可逆分支:引入辅助可逆分支以确保网络中可靠的梯度生成和参数更新。 该分支通过利用可逆架构来维护完整的信息。 然而,将其直接与主分支集成会产生大量的推理成本,从而促使设计辅助可逆分支。 通过将该分支合并到深度监督框架中,主分支可以接收可靠的梯度信息,有助于提取目标任务的相关特征。 这使得它能够在浅层和深层网络中应用,同时通过在推理过程中删除辅助分支来保留推理能力。
- 多级辅助信息:通过集成特征金字塔层级之间的集成网络来增强深度监督,允许主分支接收来自不同预测头的聚合梯度信息。 这种方法缓解了深度特征金字塔丢失目标对象预测所需的重要信息的问题,确保主分支保留用于学习跨各种目标的预测的完整信息。
# YOLOv9 head
head:
[
# multi-level auxiliary branch
# elan-spp block
[9, 1, SPPELAN, [512, 256]], # 29
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
# csp-elan block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 2]], # 32
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
# csp-elan block
[-1, 1, RepNCSPELAN4, [256, 256, 128, 2]], # 35
# main branch
# elan-spp block
[28, 1, SPPELAN, [512, 256]], # 36
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 25], 1, Concat, [1]], # cat backbone P4
# csp-elan block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 2]], # 39
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 22], 1, Concat, [1]], # cat backbone P3
# csp-elan block
[-1, 1, RepNCSPELAN4, [256, 256, 128, 2]], # 42 (P3/8-small)
# avg-conv-down merge
[-1, 1, ADown, [256]],
[[-1, 39], 1, Concat, [1]], # cat head P4
# csp-elan block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 2]], # 45 (P4/16-medium)
# avg-conv-down merge
[-1, 1, ADown, [512]],
[[-1, 36], 1, Concat, [1]], # cat head P5
# csp-elan block
[-1, 1, RepNCSPELAN4, [512, 1024, 512, 2]], # 48 (P5/32-large)
# detect
[[35, 32, 29, 42, 45, 48], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
]上面的代码片段显示了 YOLOv9 头部内部分为主分支和多级辅助分支的情况。 多级辅助分支是主分支的直接子集。 辅助分支中的复制块负责代表主分支存储梯度信息。
4、通用高效层聚合网络(GELAN)
YOLOv9 还通过引入结合了 CSPNet 和 ELAN 重要功能的通用高效层聚合网络 (GELAN),继续维护 YOLO 架构系列闻名的实时推理支持标志。
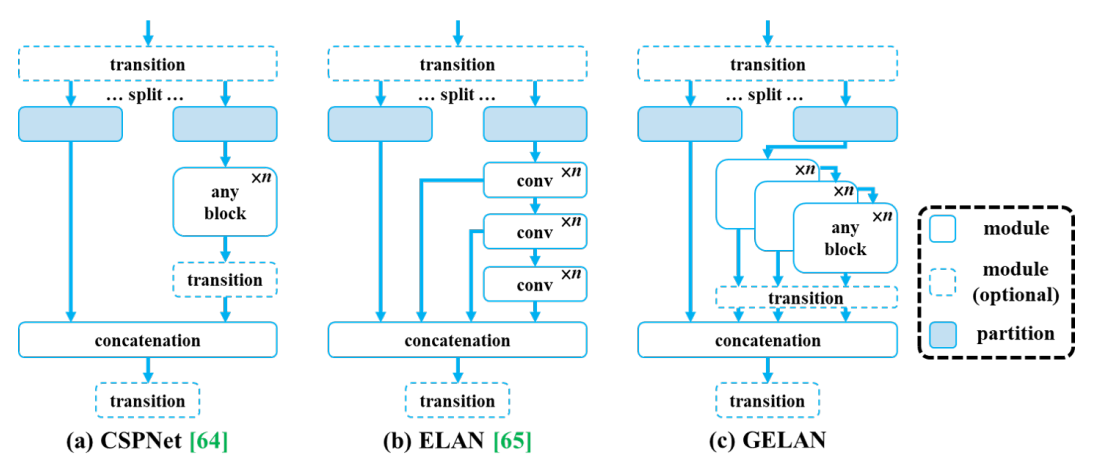
CSPNet 以其有效的梯度路径规划、增强特征提取而闻名。 另一方面,ELAN 通过使用堆叠卷积层来优先考虑推理速度。 GELAN 整合了这些优势,创建了一个强调轻量级设计、快速推理和准确性的多功能架构。 它通过启用卷积层之外的任何计算块的堆叠来扩展 ELAN 的功能,从而允许在所有层上应用推理优化。
##### GELAN #####
class SPPELAN(nn.Module):
# spp-elan
def __init__(self, c1, c2, c3): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = c3
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = SP(5)
self.cv3 = SP(5)
self.cv4 = SP(5)
self.cv5 = Conv(4*c3, c2, 1, 1)
def forward(self, x):
y = [self.cv1(x)]
y.extend(m(y[-1]) for m in [self.cv2, self.cv3, self.cv4])
return self.cv5(torch.cat(y, 1))
class RepNCSPELAN4(nn.Module):
# csp-elan
def __init__(self, c1, c2, c3, c4, c5=1): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = c3//2
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = nn.Sequential(RepNCSP(c3//2, c4, c5), Conv(c4, c4, 3, 1))
self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1))
self.cv4 = Conv(c3+(2*c4), c2, 1, 1)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend((m(y[-1])) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
#################最初的“ELAN”模块只允许堆叠卷积层。 上面代码片段中的新“SPPELAN”模块允许在“SP”块中堆叠池层,该块特别包含“MaxPool2D”层。
5、YOLOv9 vs YOLOv8 vs YOLOv7
与之前最先进的模型相比,YOLOv9 的目标检测在不同指标上都有显着的改进。 尽管与 YOLOv7 和 YOLOv8 最大的架构变体相比,YOLOv9 的参数要少得多,但在准确性方面仍然优于它们。 此外,YOLOv9 保持了与其直接前身 YOLOv7 几乎相同的计算复杂性,并避免了 YOLOv8 带来的额外复杂性。
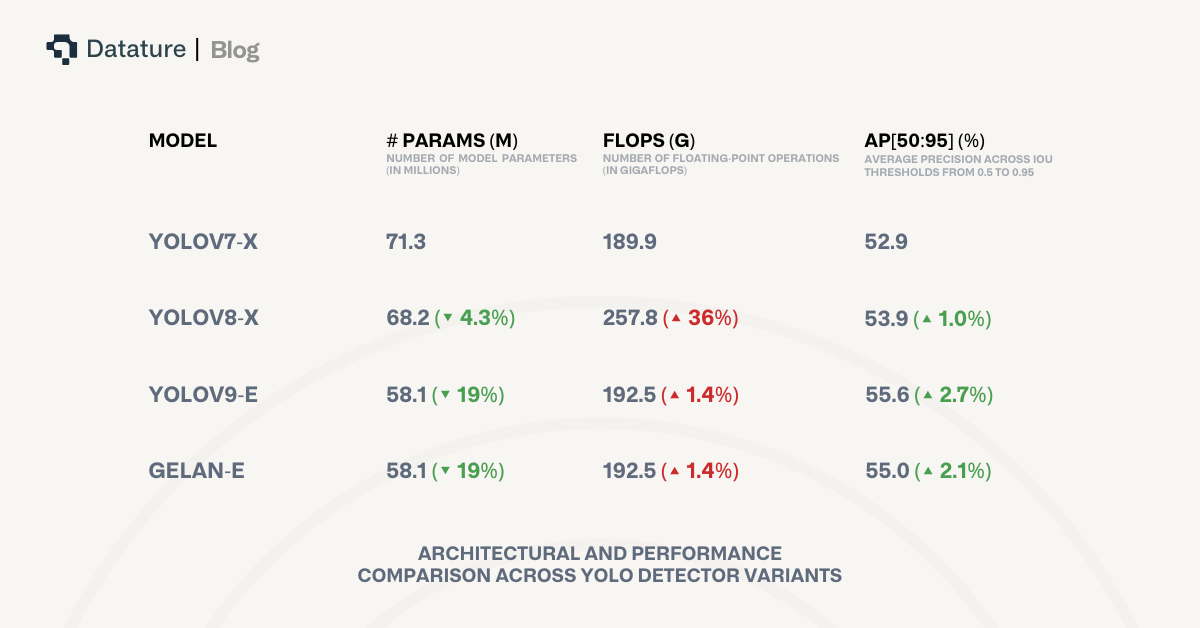
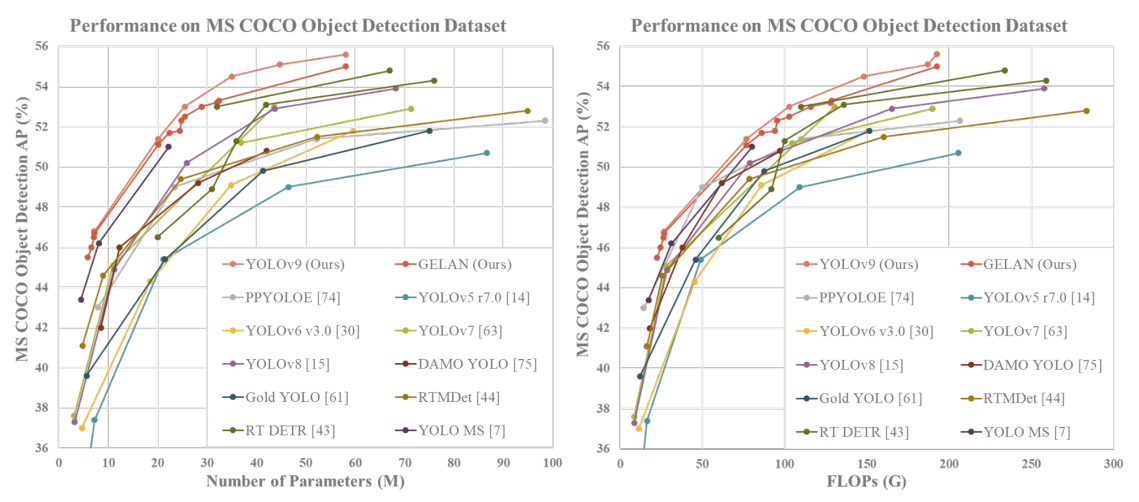
在 COCO 数据集上进行训练时,YOLOv9 甚至优于 YOLO 系列之外的其他最先进的实时目标检测器,例如 RT DETR、RTMDet 和 PP-YOLOE。 这些模型具有利用 ImageNet 预训练权重的优势。 独特的是,尽管采用了从头开始训练的方法,YOLOv9 仍然能够确保优于它们的优势,展现出快速学习鲁棒特征的强大能力。 这可能意味着在自定义数据集上训练 YOLOv9 可能会进一步提升其已经令人印象深刻的指标。
6、用于人群检测的 YOLOv9 推理示例
虽然许多性能测试和评估都是在高质量图像上完成的,但我们希望了解 YOLOv9 在真实数据上的表现如何。 我们输入了一段完全没见过的、中等质量的视频,该视频描绘了购物中心里的一群人,供模型进行预测。 输入分辨率为 640x640 的预训练 YOLOv9-E 能够检测场景中的大多数人物实例,无需任何进一步的微调,并且在遮挡方面具有良好的性能。
YOLOv9 还可以扩展到与其他 MOT 算法(例如 BYTETrack)一起使用。 在此示例中,我们为每个人和背包分配了唯一的 ID,并在他们在框架中移动时对其进行跟踪。 这为人群管理开辟了重要的用例,通过计算特定位置的人数以及监视来跟踪可疑人员的活动或识别可疑的包。 请查看我们的文章,了解有关如何将 BYTETrack 与 YOLOv9 结合使用的更多信息。

7、YOLOv9 应用
YOLOv9 的实时对象检测支持可用于各种实际应用,特别适合快节奏的环境,例如:
- 自动驾驶汽车:YOLOv9可用于自动驾驶汽车,实时检测道路上的行人、其他车辆、交通标志和障碍物,使车辆能够根据周围环境做出决策。
- 监控系统:YOLOv9 可用于监控摄像头,通过检测可疑活动、未经授权的入侵或废弃物体来监控公共空间、机场、火车站和其他区域。
- 零售分析:在零售业,YOLOv9 可用于跟踪客户动向、分析商店客流量,并通过识别货架上的产品来监控库存水平。 它还可以通过检测商店行窃事件来帮助零售安全。
8、如何根据自己的权重微调 YOLOv9?
要在自己的自定义数据集上微调 YOLOv9,你首先需要克隆 YOLOv9 存储库并安装所需的 Python 包。 我们建议你为此使用虚拟环境,例如 conda 或 virtualenvwrapper。
git clone https://github.com/WongKinYiu/yolov9.git
pip install -r requirements.txt如果你更喜欢在 Docker 容器中进行开发,请按照以下 Docker 设置说明进行操作:
# create the docker container, you can change the share memory size if you have more.
nvidia-docker run --name yolov9 -it -v your_coco_path/:/coco/ -v your_code_path/:/yolov9 --shm-size=64g nvcr.io/nvidia/pytorch:21.11-py3
# apt install required packages
apt update
apt install -y zip htop screen libgl1-mesa-glx
# pip install required packages
pip install seaborn thop
# go to code folder
cd /yolov9然后,你需要准备类似于 COCO 数据集文件结构的数据集。 如果需要引用此结构,你可以运行以下脚本,该脚本将下载 COCO 数据集的训练、验证和测试分割以及标签。
bash scripts/get_coco.sh要运行训练,由于计算要求,建议配置 GPU。
# train yolov9 models
python train_dual.py --workers 8 --device 0 --batch 16 --data data/coco.yaml --img 640 --cfg models/detect/yolov9-c.yaml --weights '' --name yolov9-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15
# train gelan models
# python train.py --workers 8 --device 0 --batch 32 --data data/coco.yaml --img 640 --cfg models/detect/gelan-c.yaml --weights '' --name gelan-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15如果希望利用多个 GPU,只需修改命令以利用“torch.distributed”:
# train yolov9 models
python -m torch.distributed.launch --nproc_per_node 8 --master_port 9527 train_dual.py --workers 8 --device 0,1,2,3,4,5,6,7 --sync-bn --batch 128 --data data/coco.yaml --img 640 --cfg models/detect/yolov9-c.yaml --weights '' --name yolov9-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15
# train gelan models
# python -m torch.distributed.launch --nproc_per_node 4 --master_port 9527 train.py --workers 8 --device 0,1,2,3 --sync-bn --batch 128 --data data/coco.yaml --img 640 --cfg models/detect/gelan-c.yaml --weights '' --name gelan-c --hyp hyp.scratch-high.yaml --min-items 0 --epochs 500 --close-mosaic 15模型训练完成后,可以运行评估脚本来评估你的模型:
# evaluate converted yolov9 models
python val.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.7 --device 0 --weights './yolov9-c-converted.pt' --save-json --name yolov9_c_c_640_val
# evaluate yolov9 models
#python val_dual.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.7 --device 0 --weights './yolov9-c.pt' --save-json --name yolov9_c_640_val
# evaluate gelan models
# python val.py --data data/coco.yaml --img 640 --batch 32 --conf 0.001 --iou 0.7 --device 0 --weights './gelan-c.pt' --save-json --name gelan_c_640_val或者,如果你希望对测试数据运行推理,可以查看此处的代码片段,或查看此 HuggingFace Space 以获得方便的仪表板,以快速评估和可视化几个图像上的推理性能。 原始 GitHub 存储库还包含你可能会觉得有用的其他区域,例如来自社区贡献的其他相关 YOLOv9 教程的链接,例如在 Tensorflow、ONNX 和 TensorRT 上实现 YOLOv9。 要阅读已发表的论文,可以访问此处的链接。
原文链接:YOLOv9 - A Comprehensive Guide and Custom Dataset Fine-Tuning
BimAnt翻译整理,转载请标明出处




