
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在我的日常工作中,作为数字协作协调员,我花费大量时间收集、检查和管理各种 BIM 数据。 很多次收到一组数据后我就无奈地举手——质量远远达不到我可以使用的程度。 然后我会开始一个普通的数据清理过程。 我无数次咒骂过这种情况——大多数建设项目的人甚至不知道如何正确处理数据! 我们从未被教导过什么是好的数据集。 也不知道如何填写 Excel 电子表格以方便数据管理。 也不知道如何用高质量的数据填充我们的模型。
让我们从一些绝对基本的东西开始,因此,我们将从难度级别开始。 那么—什么是数据?
根据维基百科的定义:
数据是单独的事实、统计数据或信息项,通常是数字。 从更技术的意义上来说,数据是关于一个或多个人或物体的一组定性或定量变量的值。
数据为我们提供有关物体或人的信息,并且可以传输或处理。 单个值(数据)通常称为数据点。 数据是我们在项目中创建的一切——从会议录音到复杂的模型。 我们项目中的一些数据示例:
- pdf 文件(例如产品数据表),
- 发送给同事的电子邮件
- 建筑工地的照片。
- 我们模型中墙壁的防火等级。
现在让我们转向不太明显的事情。
1、结构化和非结构化数据
我们产生的数据可以是结构化的或非结构化的。 这取决于它的外观以及我们如何创建它。 我在这里谈到了这个主题。 让我们从定义它们之间的区别开始。
结构化数据(或数据模型)组织数据点并定义彼此之间的关系。 顾名思义,在将其放入数据存储(例如关系数据库)之前必须有一个结构。
BIM 对象就是一个很好的例子:表示墙的数据模型由定义墙的其他元素组成:厚度、长度、防火等级、材料等。要创建墙,你必须将数据放入预定义的模式(每个 数据点到相应的数据字段)。 因此,结构化数据也称为写入时模式(schema-on-write)。 结构化数据最重要的特点是查询简单性。 尽管如此,它需要努力在数据库中创建一组数据。
坦率地说,非结构化数据就是其他任何东西。 非结构化信息没有预定义的数据模型。 它以本机文件格式存储。 相应地,非结构化数据是电子邮件、图片、pdf文档、会议记录等。非结构化数据的最大优点是其创建和存储的简单性。 然而,要查询它,用户必须了解该格式如何转换为纯信息。 因此它也被称为读时模式(schema-on-read)。 建筑工地的图片没有数据模型,只有熟悉某个主题的人才能将其转化为数据,例如楼层数、使用的材料、建筑尺寸、承载元件的类型等。
下表显示了我们在建设项目中遇到的数据示例:
| 结构化数据 | 非结构化数据 |
|---|---|
| 时间表 | 电子邮件 |
| 工程量清单 | 照片 |
| BIM 对象 | 会议录音 |
| BIM 模型 | 会议记录 |
| Excel 电子表格(取决于质量) | Excel 电子表格(取决于质量) |
| 招标文件 |
2、什么是属性?
我们已经知道项目中的数据是什么。 从现在开始,我将只关注一种类型的项目数据:BIM 模型以及我们所拥有的内容。 事实上,BIM 是关于对象的属性的。 那那些是什么? 这是一个有点哲学性且令人惊讶的深刻主题,但让我们保持简单。
属性是对象的物理或抽象特征。 物理属性表明该物体在物理世界中是什么:它的颜色、厚度、长度或它的构成材料。 抽象属性可以是例如:成本、对象的代码(例如根据 Uniclass)或控制区域代码。
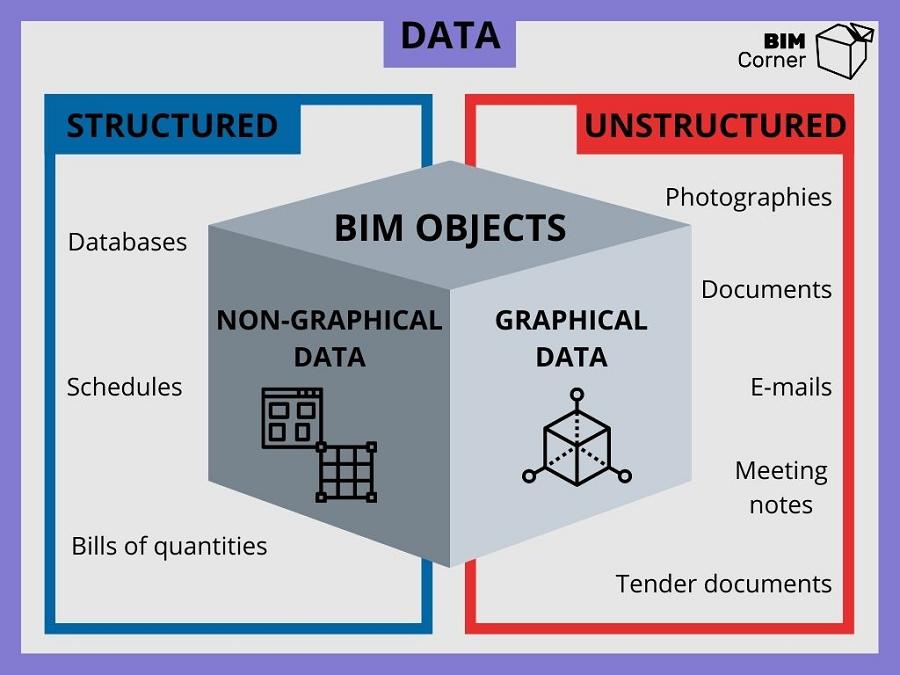
我们的项目有哪些属性? 为了回答这个问题,让我们回顾一下。 就我们在这个博客上的第一篇文章而言。 正如我在那里所描述的,我们将 BIM 数据分为图形数据和非图形数据。
2.1 图形数据
我们在屏幕上看到的只是图形数据。 这些是非结构化数据,主要用于区分不同线条或表面的含义。 此类图形数据有:
- 线的粗细
- 线型(实线、虚线、点线)
- 颜色
- 注解
- 层
- 模型形状
- 字符和符号
2.2 非图形数据
非图形数据是图纸或模型中的所有信息。 这可以是不同的时间表、房间区域或体积。 这些是直接源自图形设计的物理属性。 如果我们将 3D 设计视为表面的生硬组合,那么这正是其属性所在。
BIM 模型提供了更多此类数据。 通过将建筑元素与普通 3D 形状分离并将它们划分为类(或类别),我们可以为不同的元素分配不同的属性。 每个类别都有许多物理和抽象属性。
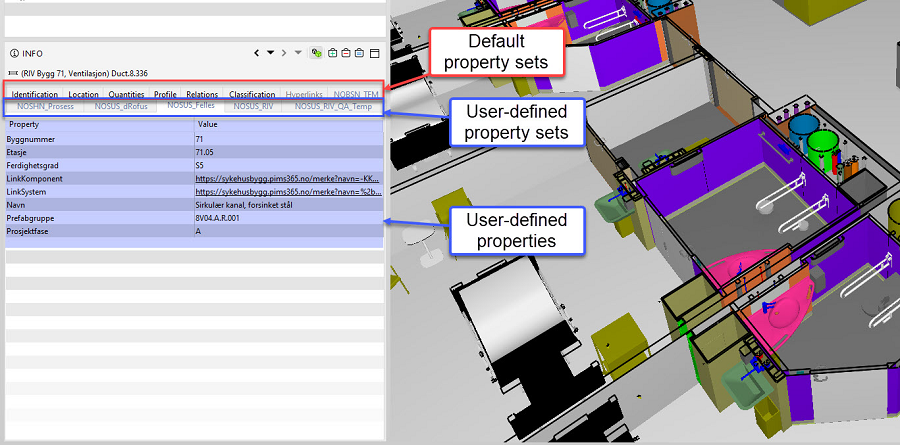
2.3 用户定义的属性
所有 BIM 创作工具以及 IFC 都附带各种预定义属性。 他们可以定义材料、数量、耐火性、轴承元件等等。 尽管项目通常需要额外的属性来满足特定的要求。 这可以是对象的责任、其在建筑物中的放置或对象的成熟度的定义。 BIM 技术使我们能够创建和定义我们想要的任何数据。 我们称它们为用户定义的属性。 我认为这个功能是 BIM 模型最强大的功能之一。
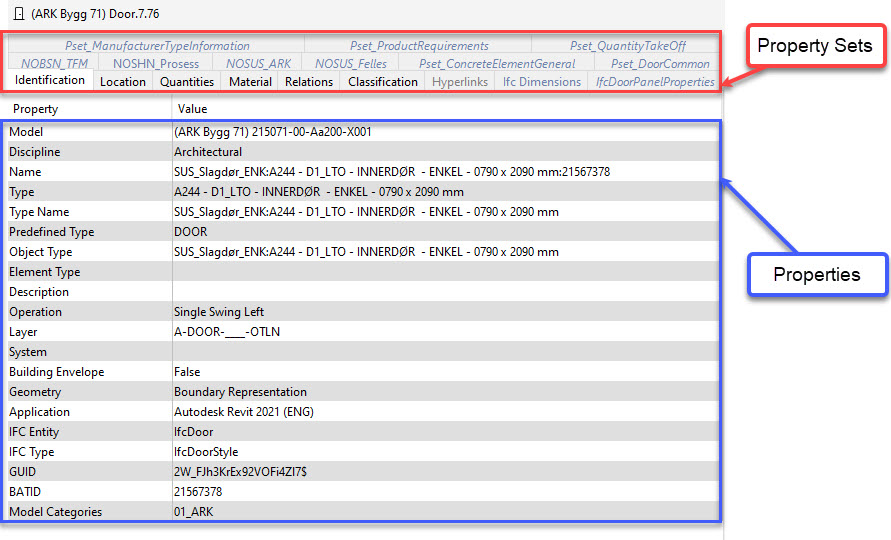
2.4 属性集
每个 BIM 对象都有数百个属性。 如果把它们依次列出来,那就太混乱了。 因此,我们使用属性集——一组属性。 IFC 模式有其分组,每个 BIM 创作工具都有自己的分组。 你可以将它们视为书籍中的章节或 Excel 电子表格中的工作表。
预定义的属性集按逻辑分组。 在 IFC 查看器中,你通常会看到属性集:标识、位置、关系或数量。
用户定义的属性集将用户定义的属性组合在一起。 此类分组应在 BEP(BIM 执行计划)中进行描述,我建议遵循一些分组规则。 否则,用户可能总是会误点击或拼错该集合(曾经在那里)。
3、什么是 BIM 模型?
为了结束这个理论介绍,现在让我们将所有这些部分结合在一起并描述什么是 BIM 模型。
首先,BIM 模型就是我们在屏幕上看到的:3D 模型,它呈现非结构化图形数据(读取模式以了解屏幕上显示的内容)。 但在后台,BIM 模型只不过是一个数据库:具有对象物理和抽象属性的非图形、结构化数据。 每个对象都是一个表,每个属性都是一列。 对象之间的关联方式与关系数据库创建连接的方式相同。
查看下面的信息图,了解数据集之间的相互关系:
4、为什么我们需要属性?
现在你应该知道什么是数据,什么是属性,项目中有哪些属性以及如何对它们进行分组。 在结束之前,我想解决最后一个问题:我们使用这些属性做什么? 我们需要项目属性有几个原因。
4.1 将所有信息集中在一处
在谈论 BIM 时,不断重复这一点。 但这确实很有帮助。 由于图形设计与非图形信息的连接,我们能够在流程上编辑数据并确保更好的数据质量。 尽管目前这可能并不完美。 BIM 设计还有很长的路要走,特别是在可用的数据类型方面(我将在下一篇文章中详细阐述该主题)。
4.2 调度和工料测量
面积和数量始终只是工料测量过程的一部分。 另一部分是掌握建筑数据、技术和施工流程。 由于设计、工程量和其他属性现在是相互关联的,工料测量已成为一项相当不那么乏味的苦差事。
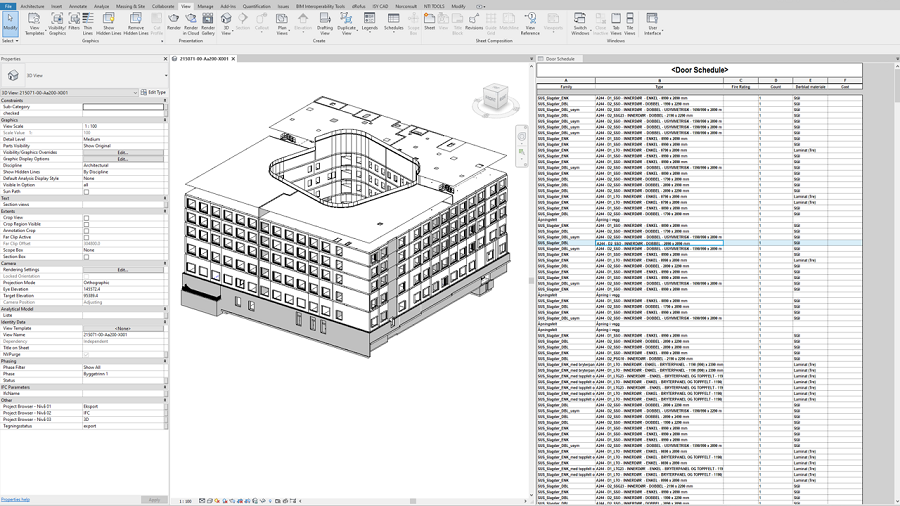
4.3 过滤
这就是属性的真正力量。 在第二章中我说过结构化数据的最大优点是查询和过滤的简单性。 BIM 模型可以轻松过滤和排序收到的信息。 通过过滤,可以查询诸如“显示我负责设计的所有对象。 向我展示所有仍处于早期设计阶段的物体。” 可以很容易地解决。
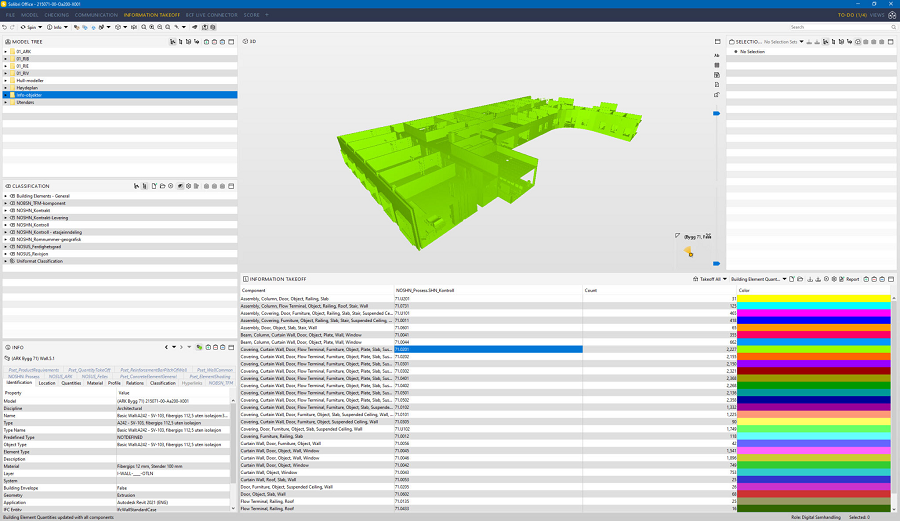
4.4 将数据导出到商业智能软件
由于 BIM 是一个数据库,属性是列,这意味着我们可以轻松地在各种类型的软件中重用我们的设计。 我们并非被迫仅通过模型进行合作。 例如,我们可以只关注数据并将我们的 BIM 数据库发送到 Power BI 等软件(。 这为我们项目的数据分析打开了一个全新的世界。
4.5 设施管理和独特的编码
越来越多的 BIM 项目考虑在 FM 阶段重用模型。 使其发挥作用的解决方案之一是为每个对象提供一个唯一的代码,该代码将以数字方式和物理对象上的形式存在。 在BIM模型中,解决方案是创建相应的用户自定义属性,该属性将在项目完成后在现场使用。 这使得设施经理能够轻松识别模型中的对象并在技术室中找到正确的设备。
5、结束语
在这篇文章中,我涵盖了大量的理论,但我尽力将我们 AEC 分支的实际示例形象化。 在下一篇文章中,我们将深入探讨数据类型的主题以及如何保持数据集干净和有用。 我看到的项目越多,我就越相信提供具有优质数据的模型的能力至关重要。
原文链接:What is data? Introduction to Data Management in BIM
BimAnt翻译整理,转载请标明出处





