
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - AI模型在线查看 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割 - 3D道路快速建模
在本文中,我们将尝试通过跟踪 2D 视频中的动作来渲染人物的 3D 动画。
在 3D 图形中制作人物动画需要大量的运动跟踪器来跟踪人物的动作,并且还需要时间手动制作每个肢体的动画。 我们的目标是提供一种节省时间的方法来完成同样的任务。
我们对这个问题的解决方案包括以下步骤:
- 2D 姿态估计:人体至少需要 17 个标志点才能完整描述其姿态。
- DeepSORT+FaceReID:跟踪姿势的运动。
- 将 2D 提升到 3D:我们从上一步获得的坐标是 2D 的。 为了以 3D 方式制作它们的动画,我们需要将这些 2 维坐标映射到 3 维空间。
- 渲染为 3D:上一步中检测到的这 17 个标志点的坐标现在将是需要动画处理的 3D 角色的四肢关节的位置。
让我们在本文的其余部分详细讨论这些步骤。
1、2D 姿态估计
如上所述,只需指定 17 个关键点(在深度学习社区中称为landmark points)即可完整描述人体姿势。 你可能已经猜到,我们正在使用深度学习来估计人类的姿势(即跨视频帧跟踪人类的姿势)。 有很多最先进的框架(例如 PoseFlow 和 AlphaPose)可以在github上找到,它们已经实现了相当准确的姿势估计。
第一个框架是由 Yuliang Xiu 等人开发的 PoseFlow。 PoseFlow 算法的基本概述是,该框架首先通过最大化视频所有帧的整体置信度来构建姿势。 下一步是使用称为非极大值抑制(通常缩写为 NMS)的技术删除检测到的冗余姿势。
可以在下面附加的 GIF 中看到,使用 PoseFlow(左侧)估计的姿势在某些帧中存在轻微故障。 这给我们带来了下一个框架:AlphaPose。 AlphaPose由Hao-Shu Fang等人开发。 该框架在帧中检测到的人周围绘制边界框,并估计他们在每个帧中的姿势。 即使一个人被另一个人部分遮挡,它也可以检测姿势。

AlphaPose 框架的代码可以在这里找到。
2、DeepSORT + FaceReID
我们使用 Alpha Pose 来检测视频中人类的姿势。 下一步是跟踪他们的动作,以便能够构建平滑的移动动画。 DeepSORT 框架的研究论文可以在这里找到。
使用 DeepSORT 和 FaceReid 边界框的输出,我们通过以下方式分离不同人的姿势。
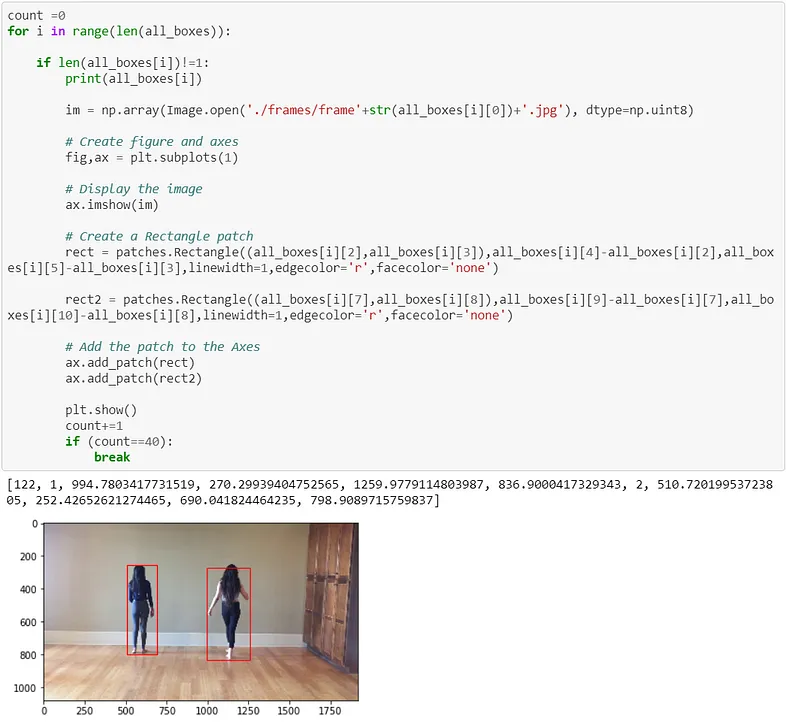

3、令人振奋的 2D 到 3D
如上所述,我们在姿态估计步骤中获得的坐标是二维的(即它们位于二维空间中)。 但为了实现 3D 动画的主要项目目标,这些坐标必须映射到 3 维空间。 这也是使用......你猜对了!......深度学习! Github 上有一个存储库以及 ICCV ’17 接受的一篇研究论文。 可以在此处找到存储库的链接。
3d-pose-baseline 存储库在 Human3.6M 数据集上训练了他们的模型。 该数据集包含约 360 万人在 17 种不同场景下的 3D 姿势及其相应图像。 简而言之,模型的输入是 360 万人类的图像,所需的输出是数据集中存在的 3D 姿势。 现在,可以构建和调整深度学习模型,直到达到相当的准确度:

4、3D 动画
一旦我们从姿势估计框架中获得了关键点的坐标,就可以将这些坐标提供给 3D 角色身体的每个肢体。 在这里,我们使用Unity作为3D动画环境来完成任务。
每帧的 17 个关键点的坐标存储在一个文本文件中,该文本文件是在 Unity 中使用 C# 读取的。 从文件中读取的坐标现在重新定位到 3D 人形模型中。 这17个关键点与Unity内置的人形头像的身体关键点进行映射。
现在,动画是使用 Unity 的逆运动学(inverse kinematics)、骨骼旋转和四元数完成的。首先看 charanim.cs 的渲染更新函数 update():
void Update()
{
if (pos == null) {
return;
}
play_time += Time.deltaTime;
int frame = s_frame + (int)(play_time * 24.057f);
if (frame > e_frame) {
play_time = 0;
frame = s_frame;
}
if (debug_cube) {
UpdateCube(frame);
}
Vector3[] now_pos = pos[frame];
Vector3 pos_forward = TriangleNormal(now_pos[7], now_pos[4], now_pos[1]);
bone_t[0].position = now_pos[0] * scale_ratio + new Vector3(init_position.x, heal_position, init_position.z);
bone_t[0].rotation = Quaternion.LookRotation(pos_forward) * init_inv[0] * init_rot[0];
for (int i = 0; i < bones.Length; i++) {
int b = bones[i];
int cb = child_bones[i];
bone_t[b].rotation = Quaternion.LookRotation(now_pos[b] - now_pos[cb], pos_forward) * init_inv[b] * init_rot[b];
}
bone_t[8].rotation = Quaternion.AngleAxis(head_angle, bone_t[11].position - bone_t[14].position) * bone_t[8].rotation;
}其中的 updateCube() 定义如下:
void UpdateCube(int frame)
{
if (cube_t == null) {
cube_t = new Transform[bone_num];
for (int i = 0; i < bone_num; i++) {
Transform t = GameObject.CreatePrimitive(PrimitiveType.Cube).transform;
t.transform.parent = this.transform;
t.localPosition = pos[frame][i] * scale_ratio;
t.name = i.ToString();
t.localScale = new Vector3(0.05f, 0.05f, 0.05f);
cube_t[i] = t;
Destroy(t.GetComponent<BoxCollider>());
}
}
else {
Vector3 offset = new Vector3(1.2f, 0, 0);
for (int i = 0; i < bone_num; i++) {
cube_t[i].localPosition = pos[frame][i] * scale_ratio + new Vector3(0, heal_position, 0) + offset;
}
}
}最终我们得到的结果如下,视频点击这里:
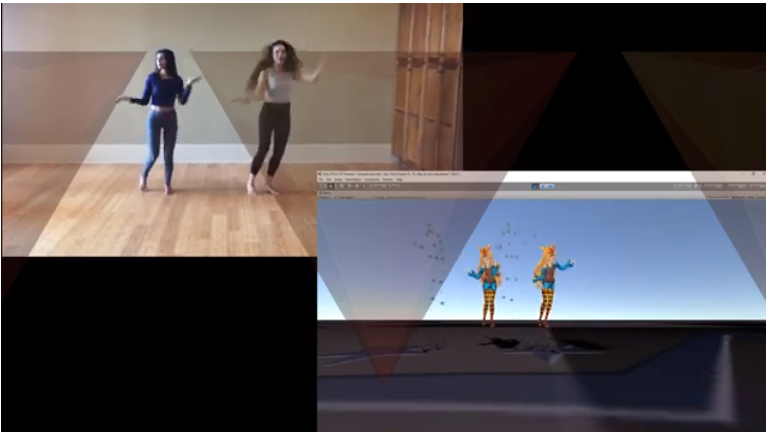
还不错!
5、结束语
总而言之,我们能够实现视频中多个人的姿势估计,并使用 Unity 等 3D 环境制作运动动画,同时还保持视频中两个不同人之间的相对位置。我们项目的 Github 存储库链接可以在这里找到。
原文链接:Transforming 2D Video to 3D Animation
BimAnt翻译整理,转载请标明出处





