
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
我对软件性能很着迷。 我在 Mapbox 的主要职责之一是寻找使我们的地图平台更快的方法。 当涉及大规模处理和显示空间数据时,没有比空间索引更有用和更重要的概念了。
空间索引是一系列排列几何数据以进行高效搜索的算法。 例如,执行“返回该区域的所有建筑物”、“查找距离该点最近的 1000 个加油站”等查询,即使搜索数百万个对象,也能在几毫秒内返回结果。
空间索引构成了 PostGIS 等数据库的基础,它是我们平台的核心。 但它们在性能至关重要的许多其他任务中也非常有用。 特别是处理遥测数据——例如 将数百万个 GPS 速度样本与道路网络进行匹配,为我们的导航服务生成实时交通数据。 在客户端,示例包括实时在地图上放置标签以及在鼠标悬停时查找地图对象。
在过去 4 年中,我构建了一堆用于空间搜索的超快速 JavaScript 库:rbush、rbush-knn、kdbush、geokdbush(未来还会有更多)。 在这篇文章中,我将尝试描述它们的幕后工作原理。
1、空间搜索问题
空间数据有两种基本查询类型:最近邻查询和范围查询。 两者都是许多几何和 GIS 问题的构建块。
1.1 K 个最近邻
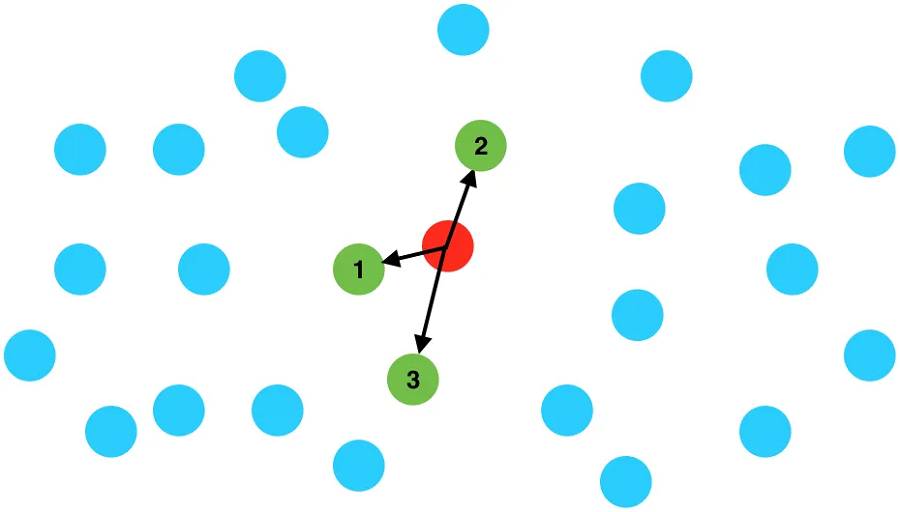
给定数千个点,例如城市位置,我们如何检索距给定查询点最近的点?
一个直观的方法是:
- 计算从查询点到每个其他点的距离。
- 按距离对这些点进行排序。
- 返回前 K 项。
如果我们有几百点就可以了。 但如果我们有数百万个查询,这些查询在实践中使用起来就会太慢。
1.2 范围和半径查询
我们如何检索在...里面的所有点
- 一个矩形? (范围查询)
- 一个圆圈? (半径查询)
简单的方法是循环遍历所有点。 但如果数据库很大并且每秒有数千个查询,这将会失败。
2、空间树的工作原理
大规模解决这两个问题需要将点放入空间索引中。 数据更改通常比查询要少得多,因此将数据处理到索引中的初始成本对于随后的即时搜索来说是一个合理的代价。
几乎所有空间数据结构都共享相同的原理来实现高效搜索:分支定界。 这意味着将数据排列在树状结构中,如果分支不符合我们的搜索条件,则可以立即丢弃它们。
2.1 R树
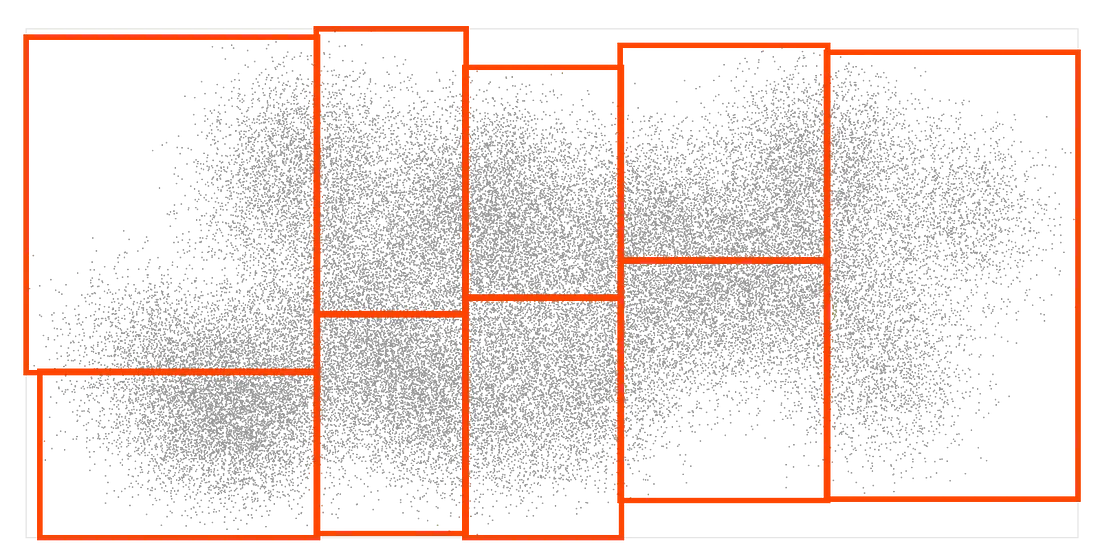
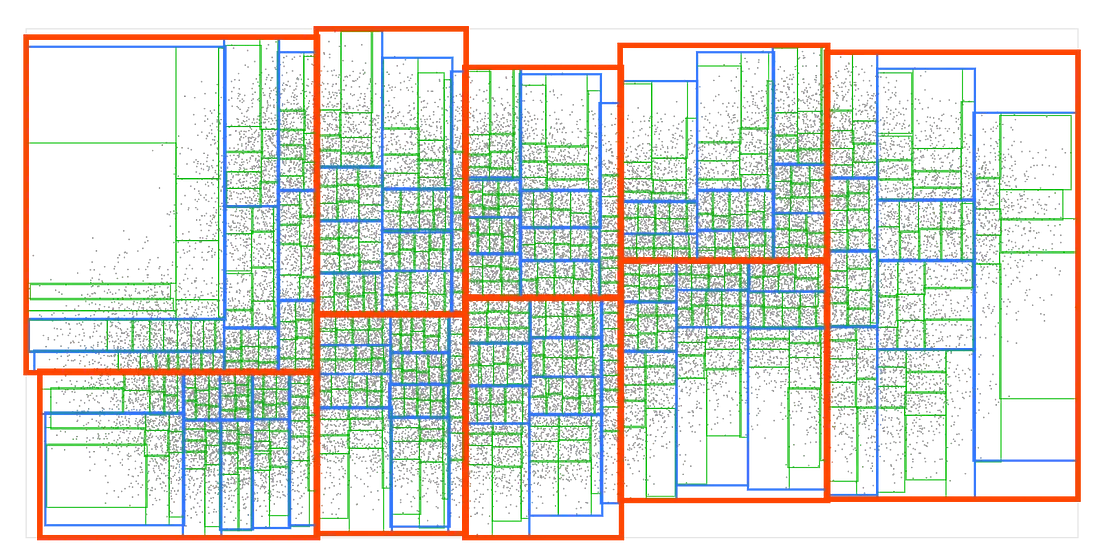
为了看看它是如何工作的,让我们从一堆输入点开始,并将它们分类到 9 个矩形框中,每个矩形框中的点数量大致相同:
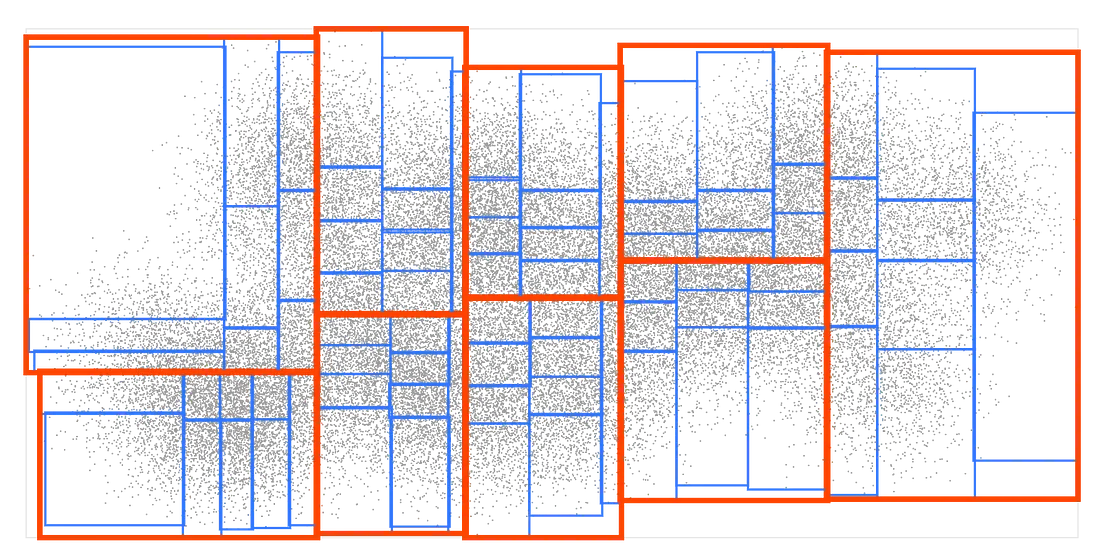
现在我们把每个盒子分成 9 个更小的盒子:
我们将重复相同的过程几次,直到最终的方框最多包含 9 个点:
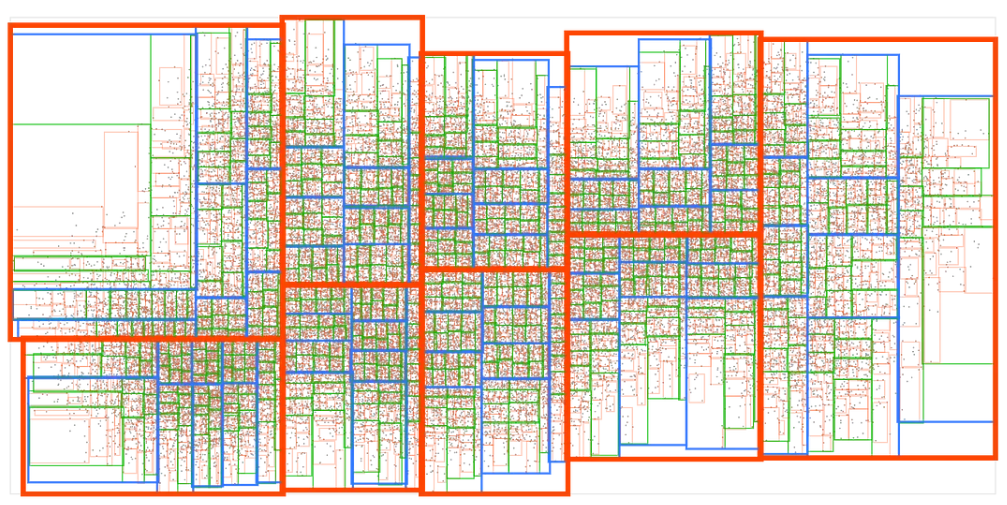
现在我们有了一个 R 树! 这可以说是最常见的空间数据结构。 所有现代空间数据库和许多游戏引擎都使用它。 R-tree 也在我的 rbush JS 库中实现。
除了点之外,R 树还可以包含矩形,而矩形又可以表示任何类型的几何对象。 它还可以扩展到 3 个或更多维度。 但为了简单起见,我们将在本文的其余部分讨论 2D 点。
2.2 K-d树
K-d树是另一种流行的空间数据结构。 kdbush,我的静态 2D 点索引 JS 库,就是基于它的。 K-d 树与 R 树类似,但我们不是将点分类到每个树级别的多个框中,而是将它们分类为两半(围绕中点)——左和右,或上和下,在 x 和 x 之间交替 y 在每个级别上进行分割。 像这样:
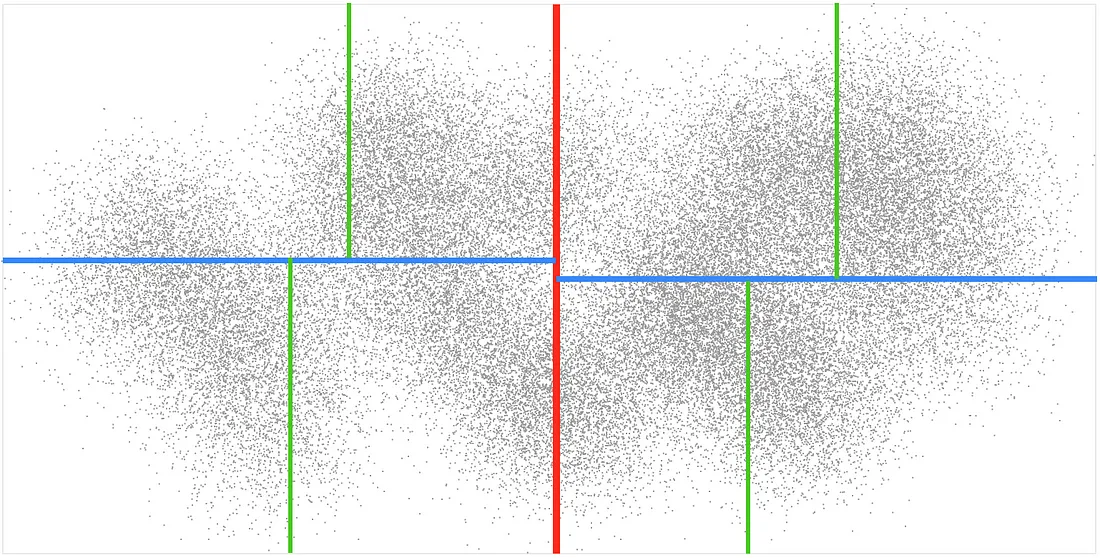
与R树相比,K-d树通常只能包含点(而不是矩形),并且不处理添加和删除点。 但它更容易实现,而且速度非常快。
R 树和 K d 树都共享将数据划分为轴对齐的树节点的原则。 因此,下面讨论的搜索算法对于两棵树来说是相同的。
3、树的范围查询
典型的空间树如下所示:
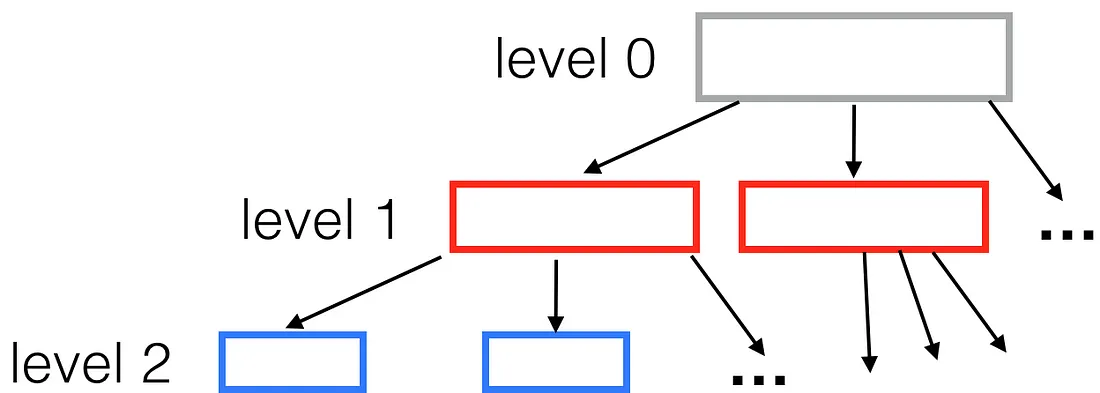
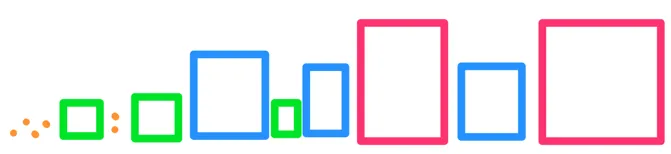
每个节点都有固定数量的子节点(在我们的 R 树示例中为 9)。 生成的树有多深? 对于一百万个点,树高将等于 ceil(log(1000000) / log(9)) = 7。
在这样的树上执行范围搜索时,我们可以从顶部树级别开始向下钻取,忽略所有不与查询框相交的框。 对于小型查询框,这意味着在树的每一层丢弃除少数框之外的所有框。 因此,获得结果不需要超过 60 个框比较 (7 * 9 = 63),而不是 100 万次。 在这种情况下,它比简单的循环搜索快约 16000 倍。
用学术术语来说,与线性搜索的 O(N) 相比,R 树中的范围搜索平均需要 O(K log(N)) 时间(其中 K 是结果数)。 换句话说,它的速度非常快。
我们选择 9 作为节点大小,因为它是一个很好的默认值,但根据经验,较高的值意味着更快的索引和更慢的查询,反之亦然。
4、K 最近邻 (kNN) 查询
邻居搜索稍微困难一些。 对于一个特定的查询点,我们如何知道要在哪些树节点上搜索最近的点呢? 我们可以进行半径查询,但我们不知道选择哪个半径——最近的点可能很远。 为了获得一些结果而进行许多半径不断增加的半径查询是低效的。
为了在空间树中搜索最近邻居,我们将利用另一种简洁的数据结构——优先级队列。 它允许以一种非常快速的方式保留项目的有序列表,以拉出“最小”的项目。 我喜欢从头开始编写东西来理解它们是如何工作的,所以这里是有史以来最好的优先级队列 JS 库:tinyqueue。
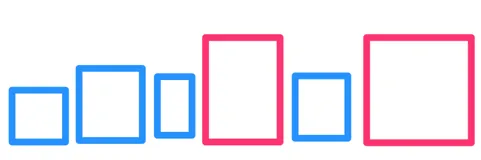
让我们再次看一下 R 树示例:
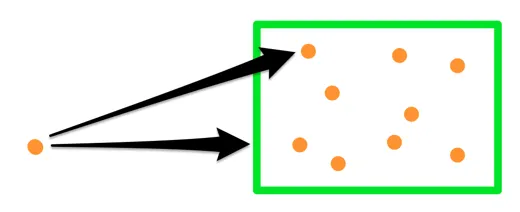
直观的观察:当我们在一组特定的框中搜索 K 个最近的点时,距离查询点越近的框更有可能包含我们要查找的点。 为了利用这一点,我们从顶层开始搜索,按照从最近到最远的顺序将最大的盒子排列到队列中:

接下来,我们“打开”最近的盒子,将其从队列中删除,并将其所有子盒子(较小的盒子)与较大的盒子一起放回到队列中:
我们就这样继续下去,每次打开最近的盒子并将其子项放回队列中。 当从队列中删除的最近的项目是实际点时,它保证是最近的点。 队列顶部的第二个点将是第二个最近的点,依此类推。
这是因为我们尚未打开的所有盒子仅包含比到该盒子的距离更远的点,因此我们从队列中提取的任何点都将比任何剩余盒子中的点更近:
如果我们的空间树非常平衡(意味着分支的大小大致相同),我们只需要处理少数盒子 - 在搜索过程中其余所有盒子都不会打开。 这使得该算法非常快。
对于 rbush,它是在 rbush-knn 模块中实现的。 对于地理点,我最近发布了另一个 kNN 库 — geokdbush,它可以优雅地处理地球曲率和日期变更线环绕。 它值得单独写一篇文章——这是我第一次在工作中应用微积分。
5、自定义 kNN 距离度量
这种拆箱方法非常灵活,并且适用于除点对点距离之外的其他距离类型。 该算法依赖于查询与框中所有对象之间定义的距离下限。 如果我们可以为自定义指标定义这个下限,我们就可以使用相同的算法。
这意味着我们可以更改算法来搜索最接近线段(而不是点)的 K 个点:
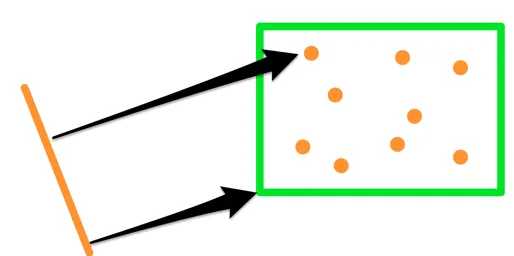
我们需要对算法进行的唯一修改是将点到点和点到框距离计算替换为段到点和段到框距离。
特别是,当我用 JS 构建 Concaveman(一个快速的 2D 凹壳库)时,这非常有用。 它需要一堆点并生成如下所示的轮廓:
该算法从凸包开始(计算速度很快),然后通过最近的点之一连接它们来向内弯曲其线段:
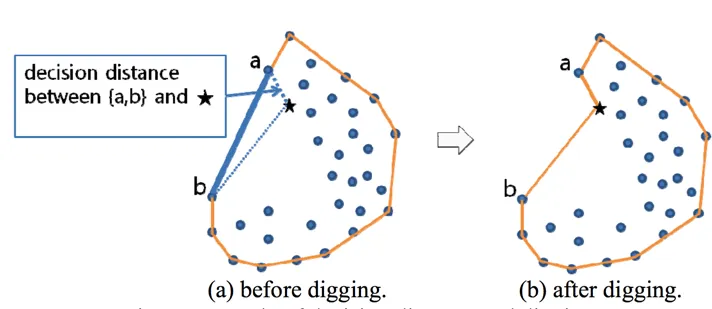
以下是关于该操作的论文的引用:
在我们提出的凹壳算法中,从边界边缘寻找最近的内部点(这些是挖掘目标点的候选点)是一个耗时的过程。 为这个过程开发更有效的方法是未来的研究课题。
我的进步是幸运的巧合! 对点进行索引并执行“最接近线段的点”查询使算法非常快。
6、结束语
在该系列的后续文章中,我将介绍将 kNN 算法扩展到地理对象,并详细介绍树打包算法(如何以最佳方式将点分类到“盒子”中)。
原文链接:A dive into spatial search algorithms
BimAnt翻译整理,转载请标明出处





