
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
人类理解语言细微差别的能力是无与伦比的。 具有洞察力的人类大脑能够很容易地理解给定句子中的幽默、讽刺、负面情绪等等。 唯一的标准是我们必须知道该句子所使用的语言。
例如,如果有人用日语评论我的文章,我当然不会明白他想说什么。 这是一般规则,不是吗? 为了有效的沟通,我们需要用听者最理解的语言与他/她互动。
对于机器来说,要处理和理解任何类型的文本,重要的是我们用机器可以理解的语言来表示该文本。 你认为机器最能理解哪种语言? 是的,就是数字。 机器只能处理数字,无论我们向它提供什么数据:视频、音频、图像或文本。 这就是为什么将文本表示为数字或所谓的嵌入文本是最活跃的研究主题之一。
在本文中,我将介绍 Python 代码中最重要的 4 个句子嵌入技术。 此外,我将本文的范围限制为概述其架构以及如何在 Python 中实现这些技术。 我们将采用在给定句子中查找相似句子的基本用例,并演示如何使用此类技术来实现相同的目的。 我将从单词和句子嵌入的概述开始。
0、嵌入:从单词到句子
最初的嵌入技术仅处理单词(Word Embedding)。 给定一组单词,你将为该组中的每个单词生成一个嵌入。 最简单的方法是对所提供的单词序列进行 one-hot 编码,以便每个单词用 1 表示,其他单词用 0 表示。虽然这在表示单词和其他简单文本处理任务方面很有效,但它并没有真正起作用。 更复杂的,例如查找相似的单词。
例如,如果我们搜索查询:德里最好的意大利餐厅,我们希望获得与意大利美食、德里餐厅和最佳相对应的搜索结果。 然而,如果我们得到的结果是:德里的顶级意大利美食,我们的简单方法将无法检测“最佳”和“顶级”之间或“食物”和“餐厅”之间的相似性。
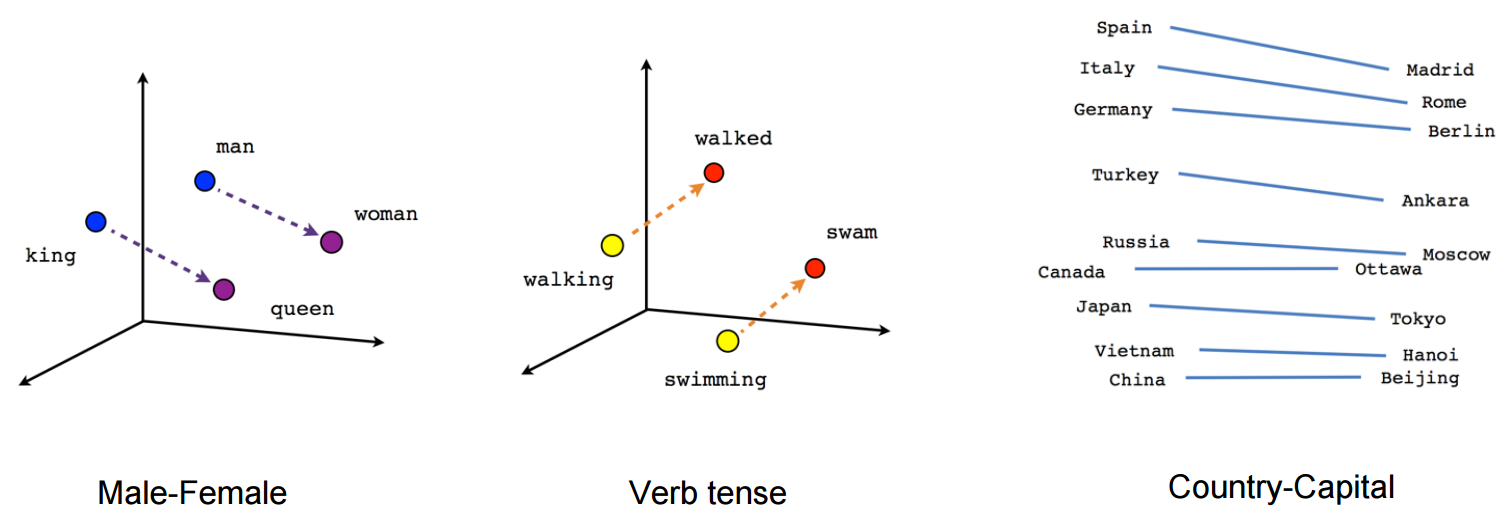
这个问题催生了我们现在所说的单词嵌入。 基本上,单词嵌入不仅可以转换单词,还可以识别单词的语义和语法,以构建该信息的向量表示。 一些流行的词嵌入技术包括 Word2Vec、GloVe、ELMo、FastText 等。
基本概念是使用来自与该单词相邻的单词的信息。 单词嵌入技术出现了突破性的创新,研究人员找到了更好的方法来表示越来越多的单词信息,并可能将其扩展为不仅表示单词,还表示整个句子和段落。
0.1 什么是句子嵌入?
在NLP中,句子嵌入(Sentence Embedding)是指以实数向量形式对句子进行数字表示,它编码有意义的语义信息。 它可以通过测量这些向量之间的距离或相似性来比较句子相似性。 通用句子编码器 (USE: Universal Sentence Encoder) 等技术使用在大型语料库上训练的深度学习模型来生成这些嵌入,这些嵌入可应用于文本分类、聚类和相似性匹配等任务。
如果我们可以直接处理单个句子,而不是处理单个单词,会怎么样? 在文本较大的情况下,仅使用单词会非常乏味,而且我们会受到从单词嵌入中提取的信息的限制。
假设,我们遇到“我不喜欢拥挤的地方”这样的句子,几句话后,我们读到“但是,我喜欢世界上最繁忙的城市之一,纽约”。 如何让机器在“拥挤的地方”和“繁忙的城市”之间做出推断?
显然,单词嵌入在这里是不够的,因此,我们使用句子嵌入。 句子嵌入技术将整个句子及其语义信息表示为向量。 这有助于机器理解整个文本中的上下文、意图和其他细微差别。
0.2 句子嵌入模型
句子嵌入模型旨在将句子的语义本质封装在固定长度的向量中。 与传统的词袋 (BoW) 表示或 one-hot 编码不同,句子嵌入捕获单词之间的上下文、含义和关系。 这种转变对于让机器掌握人类语言的微妙之处至关重要。
可以采用多种方法来生成句子嵌入:
- 平均词嵌入:这种方法涉及取句子内词嵌入的平均值。 虽然简单,但它可能无法捕捉复杂的上下文细微差别。
- BERT 等预训练模型:BERT(来自 Transformers 的双向编码器表示)等模型彻底改变了句子嵌入。 基于 BERT 的模型会考虑句子中每个单词的上下文,从而产生丰富的上下文感知嵌入。
- 基于神经网络的方法:Skip-Thought 向量和 InferSent 是基于神经网络的句子嵌入模型的示例。 他们接受训练来预测周围的句子,这鼓励他们理解句子语义。
值得注意的句子嵌入模型 - BERT(来自 Transformers 的双向编码器表示):BERT 为句子嵌入树立了基准,为各种 NLP 任务提供预训练模型。 它的双向注意力和情境理解使其成为一个突出的选择。
- RoBERTa:RoBERTa 是 BERT 的演变,它微调了其训练方法,在多个 NLP 任务中实现了最先进的性能。
- USE(通用句子编码器):由 Google 开发,USE 生成可用于各种应用程序的文本嵌入,包括跨语言任务。
0.3 句子嵌入开发库
就像单词嵌入一样,句子嵌入也是一个非常受欢迎的研究领域,它拥有非常有趣的技术,可以打破帮助机器理解我们的语言的障碍。
- Doc2Vec
- SentenceBERT
- InferSent
- Universal Sentence Encoder
我们假设你事先了解词嵌入和其他基本 NLP 概念。现在让我们开始吧,先安装一些基本的开发库并定义我们的句子列表。
首先,导入库并下载punkt:
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
import numpy as np然后,我们定义句子列表。 可以使用更大的列表 —最好使用句子列表,以便更容易处理每个句子:
sentences = ["I ate dinner.",
"We had a three-course meal.",
"Brad came to dinner with us.",
"He loves fish tacos.",
"In the end, we all felt like we ate too much.",
"We all agreed; it was a magnificent evening."]我们还将保留这些句子的标记化版本:
import nltk
nltk.download('punkt')
from nltk.tokenize import word_tokenize
import numpy as np
sentences = ["I ate dinner.", "We had a three-course meal.", "Brad came to dinner with us.", "He loves fish tacos.","In the end, we all felt like we ate too much.","We all agreed; it was a magnificent evening."]
# Tokenization of each document
tokenized_sent = []
for s in sentences:
tokenized_sent.append(word_tokenize(s.lower()))
print(tokenized_sent)结果如下:

最后,我们定义一个返回两个向量之间的余弦相似度的函数:
def cosine(u, v):
return np.dot(u, v) / (np.linalg.norm(u) * np.linalg.norm(v))让我们首先探索句子嵌入技术。
1、Doc2Vec
Doc2Vec 嵌入是 Word2Vec 的扩展,是最流行的技术之一。 它于 2014 年推出,是一种无监督算法,通过引入另一个“段落向量”来添加到 Word2Vec 模型中。 此外,还有两种方法可以将段落向量添加到模型中。
- PVDM(段落向量的分布式内存版本)
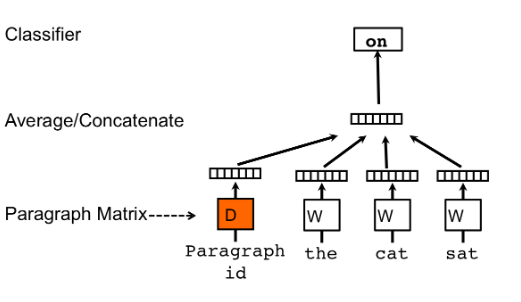
我们分配一个段落向量句子,同时在所有句子之间共享词向量。 然后我们对(段落向量和单词向量)进行平均或连接以获得最终的句子表示。 如果你注意到的话,它是 Word2Vec 的连续词袋类型的扩展,我们在给定一组单词的情况下预测下一个单词。 只是在 PVDM 中,我们根据给定的一组句子来预测下一个句子。
- PVDOBW(段落向量的分布式词袋版本)
就像PVDM一样,PVDOBW是另一个扩展,这次是Skip-gram类型。 在这里,我们只是从句子中随机抽取单词,并使模型预测它来自哪个句子(分类任务)。
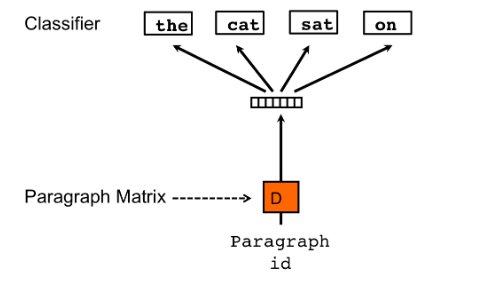
该论文的作者建议结合使用两者,但指出通常 PVDM 对于大多数任务来说已经足够了。
我们将使用 Gensim 来展示如何使用 Doc2Vec 的示例。 此外,我们已经有了一个句子列表。 我们将首先导入模型和其他库,然后构建一个标记句子语料库。 现在,每个句子都表示为 TaggedDocument,其中包含其中的单词列表以及与其关联的标签。
# import
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
tagged_data = [TaggedDocument(d, [i]) for i, d in enumerate(tokenized_sent)]
tagged_data结果如下:

然后我们使用如下参数训练模型:
## Train doc2vec model
model = Doc2Vec(tagged_data, vector_size = 20, window = 2, min_count = 1, epochs = 100)
'''
vector_size = Dimensionality of the feature vectors.
window = The maximum distance between the current and predicted word within a sentence.
min_count = Ignores all words with total frequency lower than this.
alpha = The initial learning rate.
'''
## Print model vocabulary
model.wv.vocab结果如下:

我们现在采用一个新的测试句子,并从我们的数据中找到前 5 个最相似的句子。 我们还将按照相似度递减的顺序显示它们。 infer_vector 方法返回测试句子的向量化形式(包括段落向量)。 most_similar方法返回相似的句子:
test_doc = word_tokenize("I had pizza and pasta".lower())
test_doc_vector = model.infer_vector(test_doc)
model.docvecs.most_similar(positive = [test_doc_vector])
'''
positive = List of sentences that contribute positively.
'''结果如下:

2、SentenceBERT
目前,SentenceBERT 是该领域的领先者,于 2018 年推出,并立即占据了句子嵌入的杆位。 这个基于 BERT 的模型的核心有 4 个关键概念:
- Attention:注意力
- Transformers
- Bert
- Siamese Network
Sentence-BERT 使用类似 Siamese 网络的架构来提供 2 个句子作为输入。 然后将这 2 个句子传递给 BERT 模型和池化层以生成它们的嵌入。 然后使用这对句子的嵌入作为输入来计算余弦相似度。
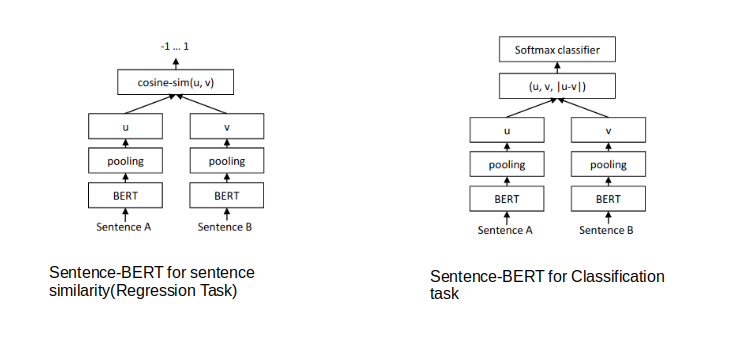
我们可以使用以下命令安装 Sentence BERT:
!pip install sentence-transformers然后我们将加载预训练的 BERT 模型。 还有许多其他预训练模型可用。 你可以在此处找到完整的型号列表。
from sentence_transformers import SentenceTransformer
sbert_model = SentenceTransformer('bert-base-nli-mean-tokens')然后我们将对提供的句子进行编码。 我们还可以显示句子向量(只需取消下面代码的注释):
sentence_embeddings = model.encode(sentences)
#print('Sample BERT embedding vector - length', len(sentence_embeddings[0]))
#print('Sample BERT embedding vector - note includes negative values', sentence_embeddings[0])然后我们将定义一个测试查询并对其进行编码:
query = "I had pizza and pasta"
query_vec = model.encode([query])[0]然后我们将使用 scipy 计算余弦相似度。 我们将检索句子和测试查询之间的相似度值:
for sent in sentences:
sim = cosine(query_vec, model.encode([sent])[0])
print("Sentence = ", sent, "; similarity = ", sim)结果如下:

好了,我们已经获得了文本中的句子和测试句子之间的相似度。 需要注意的一个关键点是,如果你想从头开始训练 SentenceBERT,它会相当慢。
3、InferSent
InferSent 是 Facebook AI Research 于 2018 年提出的一种监督句子嵌入技术。 该模型的主要特点是它是在自然语言推理(NLI)数据上进行训练的,更具体地说,是在 SNLI(斯坦福自然语言推理)数据集上进行训练。 它由 57 万个人类生成的英语句子对组成,手动标记为三个类别之一:蕴涵(Entailment)、矛盾(Contradiction)或中性(Neutral)。
就像 SentenceBERT 一样,我们采用一对句子并对它们进行编码以生成实际的句子嵌入。 然后,使用以下方法提取这些嵌入之间的关系:
- 级联
- 元素乘积
- 绝对元素差异
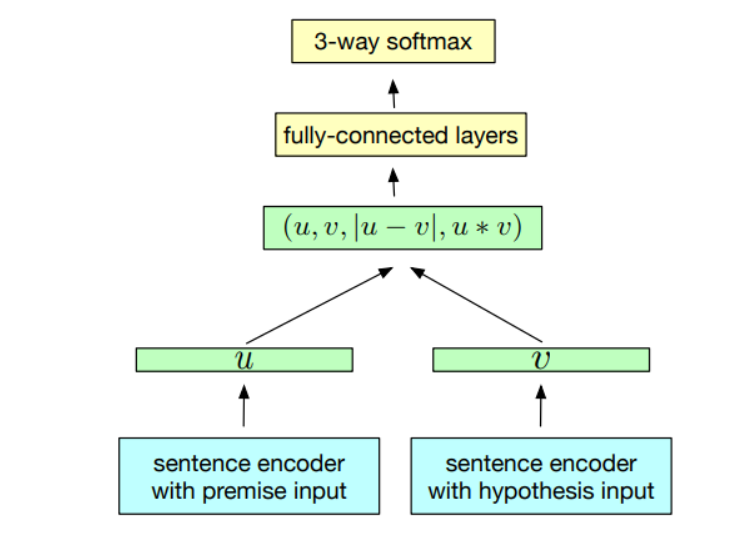
然后,这些操作的输出向量被馈送到分类器,该分类器将向量分类为上述 3 个类别之一。 实际论文提出了各种编码器架构,主要集中在 GRU、LSTM 和 BiLSTM 周围。
另一个重要特征是 InferSent 使用 GloVe 向量进行预训练的词嵌入。 InferSent 的最新版本(称为 InferSent2)使用 fastText。
让我们看看句子相似度任务如何使用 InferSent 进行工作。 为此,我们将使用 PyTorch,因此请确保你安装了最新的 PyTorch 版本。
如上所述,InferSent 有 2 个版本。 版本 1 使用 GLovE,而版本 2 使用 fastText 向量。 你可以选择使用任何模型(我使用的是版本 2)。 因此,我们下载了 InferSent 模型和预训练的词向量。 为此,请首先从此处保存 models.py 文件并将其存储在您的工作目录中。
我们还需要保存训练好的模型和预训练的 GLoVe 词向量。 根据下面的代码,我们的工作目录应该有一个“encoders”文件夹和一个名为“GLoVe”的文件夹。 编码器文件夹将包含我们的模型,而 GloVe 文件夹应包含词向量:
! mkdir encoder
! curl -Lo encoder/infersent2.pkl https://dl.fbaipublicfiles.com/infersent/infersent2.pkl
! mkdir GloVe
! curl -Lo GloVe/glove.840B.300d.zip http://nlp.stanford.edu/data/glove.840B.300d.zip
! unzip GloVe/glove.840B.300d.zip -d GloVe/然后我们加载模型和词嵌入:
from models import InferSent
import torch
V = 2
MODEL_PATH = 'encoder/infersent%s.pkl' % V
params_model = {'bsize': 64, 'word_emb_dim': 300, 'enc_lstm_dim': 2048,
'pool_type': 'max', 'dpout_model': 0.0, 'version': V}
model = InferSent(params_model)
model.load_state_dict(torch.load(MODEL_PATH))
W2V_PATH = '/content/GloVe/glove.840B.300d.txt'
model.set_w2v_path(W2V_PATH)然后,我们从一开始定义的句子列表中构建词汇表:
model.build_vocab(sentences, tokenize=True)结果如下:

与之前一样,我们有测试查询,然后使用 InferSent 对该测试查询进行编码并为其生成嵌入:
query = "I had pizza and pasta"
query_vec = model.encode(query)[0]
query_vec结果如下:

最后,我们计算该查询与文本中每个句子的余弦相似度:
similarity = []
for sent in sentences:
sim = cosine(query_vec, model.encode([sent])[0])
print("Sentence = ", sent, "; similarity = ", sim)结果如下:

4、USE - Universal Sentence Encoder
目前性能最好的句子嵌入技术之一是USE(通用句子编码器)。 对于任何人来说,谷歌提出这个建议都不足为奇。 这里的关键特征是我们可以将其用于多任务学习。
这意味着我们生成的句子嵌入可以用于多种任务,例如情感分析、文本分类、句子相似度等,然后这些请求的结果会反馈到模型以获得比之前更好的句子向量。
最有趣的部分是这个编码器基于两个编码器模型,我们可以使用这两个模型中的任何一个:
- Transformer
- 深度平均网络(DAN)
这两种模型都能够将单词或句子作为输入并为其生成嵌入。 以下是基本流程:
- 将句子转换为小写后对其进行标记(Tokenize)
- 根据编码器的类型,句子会转换为 512 维向量:
- 如果我们使用 Transformer,它类似于 Transformer 架构的编码器模块,并使用 self-attention 机制。
- DAN 选项首先计算一元嵌入和二元嵌入,然后对它们进行平均以获得单个嵌入。 然后将其传递给深度神经网络以获得 512 维的最终句子嵌入。
- 然后,这些句子嵌入用于各种无监督和监督任务,例如 Skipthoughts、NLI 等。然后再次重用训练好的模型来生成新的 512 维句子嵌入。
要开始使用 USE 嵌入,我们首先需要安装 TensorFlow 和 TensorFlow hub:
!pip3 install --upgrade tensorflow-gpu
# Install TF-Hub.
!pip3 install tensorflow-hub首先,我们将导入以下必要的库:
import tensorflow as tf
import tensorflow_hub as hub
import numpy as np我们可以通过 TFHub 获取该模型。 让我们加载模型:
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
model = hub.load(module_url)
print ("module %s loaded" % module_url)结果如下:

然后我们将为句子列表和查询生成嵌入。 这就像将句子传递给模型一样简单:
sentence_embeddings = model(sentences)
query = "I had pizza and pasta"
query_vec = model([query])[0]最后,我们将计算测试查询和句子列表之间的相似度:
module_url = "https://tfhub.dev/google/universal-sentence-encoder/4"
model = hub.load(module_url)
print ("module %s loaded" % module_url)结果如下:

5、结束语
我们看到了 NLP 中最重要的 4 种句子嵌入技术以及使用它们来查找文本相似性的基本代码。 我强烈建议你使用更大的数据集,并在该数据集上尝试使用这些模型来执行其他 NLP 任务。 另外,这只是计算句子相似度的基本代码。 对于合适的模型,你需要首先预处理这些句子,然后将它们转换为嵌入。
原文链接:Top 4 Sentence Embedding Techniques using Python
BimAnt翻译整理,转载请标明出处





