
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
由于深度神经网络的进步,文本到图像模型于 2010 年代中期出现。 然而,早在 ChatGPT 出现之前,围绕生成式 AI 的讨论就随着文本到图像模型 OpenAI 的 DALL-E、Google Brain 的 Imagen 和 StabilityAI 的 Stable Diffusion 的出现而增长。 这些生成式人工智能模型由于类似于真实照片和手绘艺术品而引起了人们的关注。
在本文中,让我们来看看可以为你提供帮助的六大开源图像生成模型。如果你需要在WebGL应用中为3D模型自动设置AI生成的纹理,可以是用DreamTexture.js开发包,非常方便:

1、DeepFloyd IF
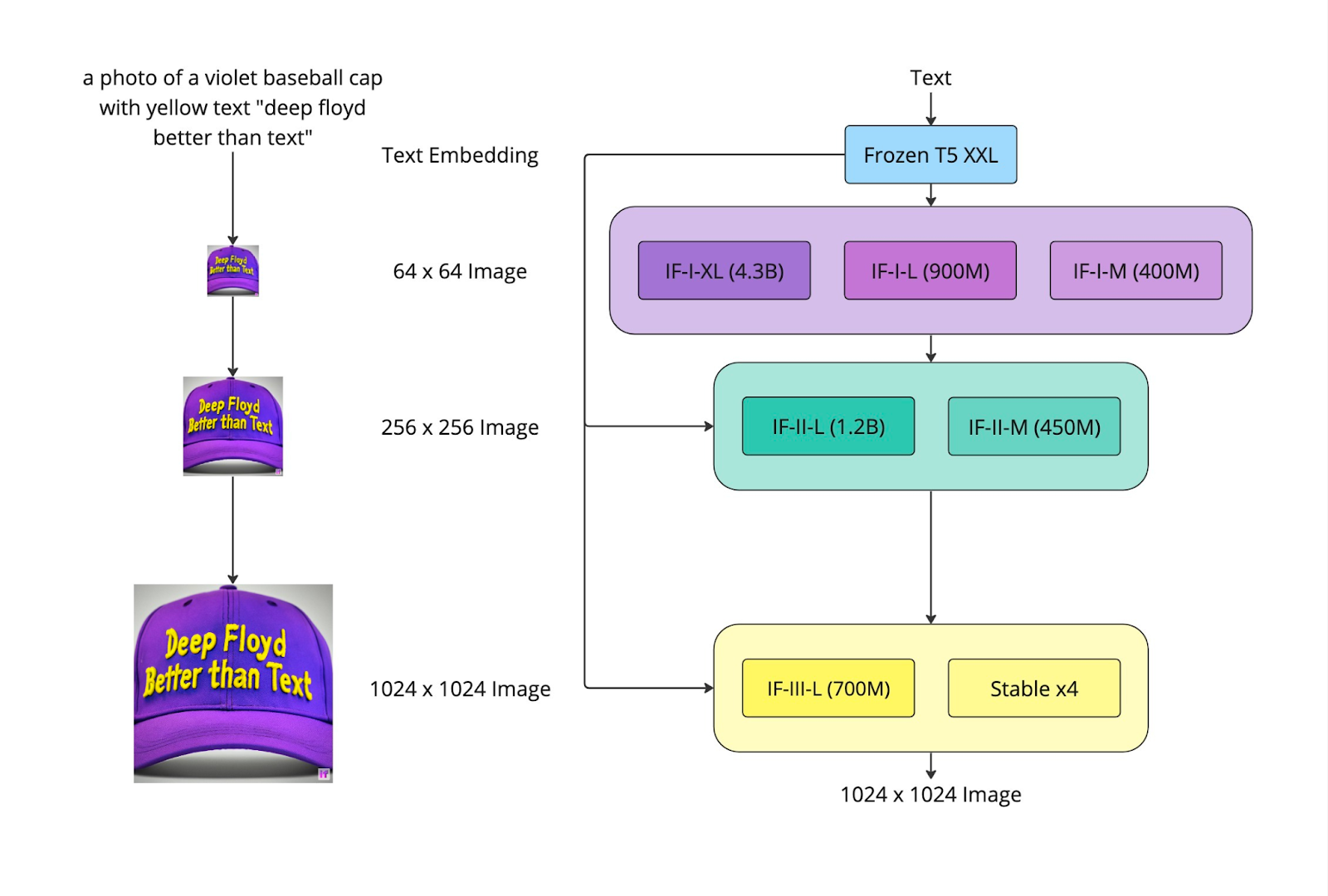
在 Stability AI 的支持下,DeepFloyd 研究小组的开源文本到图像模型 DeepFloyd IF 结合了逼真的视觉效果和语言理解。 它采用模块化设计,具有固定的文本编码器和三个互连的像素扩散模块。 初始模块根据文本提示生成 64×64 px 图像,而后续超分辨率模块则创建分辨率不断增加的图像:256×256 px 和 1024×1024 px。 整个模型利用源自 T5 转换器的冻结文本编码器来提取文本嵌入。 然后将这些嵌入用于 UNet 架构,并通过交叉注意力和注意力池进行增强。 结果,该模型超越了现有模型,在 COCO 数据集上取得了令人印象深刻的零样本 FID 分数 6.66。
可以在这里查看DeepFloyd IF的 GitHub 存储库。
2、Stable Diffusion
潜在文本到图像模型 Stable Diffusion v1-5 将自动编码器与扩散模型合并,以创建照片般逼真的图像。 它已经在广泛的 laion-aesthetics v2 5+ 数据集上进行了训练,并在 512×512 像素的分辨率下微调了超过 595k 步,该模型具有基于任何给定文本输入生成高度逼真的图像的卓越能力。

Stable Diffusion可以灵活地从各种潜在空间生成图像,而不是局限于一组固定的文本提示。 它对大型图像数据集的训练使其能够更深入地了解图像特征,从而生成更逼真的图像。
Stable Diffusion v1-5 可在 Diffusers 库和 RunwayML GitHub 存储库中访问。 可以访问这里查看源码。
3、Openjourney
Openjourney 是一个免费的开源文本到图像模型,它在超过 124k Midjourney v4 图像的数据集上进行训练,以 Midjourney 风格生成 AI 艺术。 这是稳定扩散的微调。

Openjourney 由领先的提示工程网站 PromptHero 开发,是 HuggingFace 上下载量第二高的文本到图像模型,仅次于 Stable Diffusion。 用户更喜欢 Openjourney,因为它能够以最少的输入生成令人印象深刻的图像,并且适合作为微调的基本模型。
单击此处访问Openjourney模型。
4、Dream Shaper
深受粉丝喜爱的 Dream Shaper V7 基于扩散模型架构构建,引入了 LoRA 支持和整体真实感方面的改进。 它建立在版本 6 中的增强功能的基础上,其中包括增加的 LoRA 支持、总体样式改进以及更好的 1024 像素高度生成(尽管建议在使用此功能时小心)。

Dream Shaper生成具有噪声抵消的逼真图像,并通过 booru 标签增强动漫风格的生成。 它还提高了较低分辨率下的眼睛性能,作为早期版本的“修复”。 3.32 版“剪辑修复”的影响可能与 3.31 版有所不同,建议将其用于混音。 它还涉及修复和修复。
如果想了解有关Dream Shaper的更多信息,请查看此内容。
5、Dreamlike Photoreal
Dreamlike Photoreal 2.0 是基于稳定扩散 1.5 的真实感模型。 由 DreamlikeArt 制作,你可以通过将照片合并到提示中来增强生成图像的真实感。

为了获得最佳结果,请使用非方形纵横比。 对于肖像风格的照片,建议使用垂直纵横比,而水平纵横比更适合风景照片。 Dreamlike Photoreal模型是在尺寸为 768×768 像素的图像上进行训练的,尽管它也可以有效处理更高分辨率(如 768x1024px 或 1024x768px)。
Dreamlike Photoreal在服务器级 A100 GPU 上运行,平均生成速度为 4 秒,超越 8 倍 RTX 3090 GPU 的性能。 它能够同时处理多达 30 个图像并同时生成多达 4 个图像,确保了高效的工作流程。 它包括多种功能,如放大、自然语言编辑、面部增强、姿势、深度、草图复制等。
可以在这里访问Dreamlike Photoreal模型。
6、Waifu Diffusion
最后但并非最不重要的一点是,我们有 Waifu Diffusion,它是稳定扩散模型的微调版本 (1.3),源自稳定扩散 v1.4。 该模型专门用于生成逼真的动漫风格图像,并因其令人印象深刻的多样性和高品质而获得认可。

Waifu Diffusion模型在从 booru 网站获得的 680k 文本图像样本数据集上进行训练。可以在这里查看Waifu Diffusion的 GitHub 存储库。
原文链接:Top 6 Open Source Text-to-Image Models
BimAnt翻译整理,转载请标明出处





